异步,多线程,任务和并行
了解异步的实质,任务的实质,以及为什么有了任务还需要一个并行类(Parallel)等问题. 如何优雅地控制现场,并且处理任务和并行中的异常.
建议71:区分异步和多线程应用场景.
初学者有时候会将异步和多线程混为一谈。如果对它们之间的区别不是很清楚,很容易写出下面这样的代码:
private void buttonGetPage_Click(object sender, EventArgs e)
{
Thread t = new Thread(() =>
{
var request = HttpWebRequest.Create("http://www.cnblogs.com/luminji");
var response = request.GetResponse();
var stream = response.GetResponseStream();
using(StreamReader reader = new StreamReader(stream))
{
var content = reader.ReadLine();
if (textBoxPage.InvokeRequired)
textBoxPage.BeginInvoke(new Action(() =>
{
textBoxPage.Text = content;
}));
else
textBoxPage.Text = content;
}
});
t.Strat();
}
上面的代码模拟了在一个Winform窗体程序中,单击Button获取某个网页的内容并显示出来。可以预见,如果该网页的内容很多,或者当前的网络状况不太好,获取网页的过程会持续较长时间。于是,我们可能会想到用新起工作线程的方法来完成这项工作,这样在等待网页内容返回的过程中Winform界面就不会被阻滞了。是的,上面的程序解决了界面阻滞的问题,但是,它高效吗?答案是:不。要理解这一点,需要从“IO操作的DMA (Direct Memory Access)模式”开始讲起。DMA即直接内存访问,是一种不经过CPU而直接进行内存数据存储的数据交换模式。通过DMA的数据交换几乎可以不损耗CPU的资源。在硬件中,硬盘、网卡、声卡、显卡等都有DMA功能。CLR所提供的异步编程模型就是让我们充分利用硬件的DMA功能来释放CPU的压力。
了解这一点,再来重新审视本建议开头的这个例子。其开头部分的示例代码可以用图6-1来阐述。
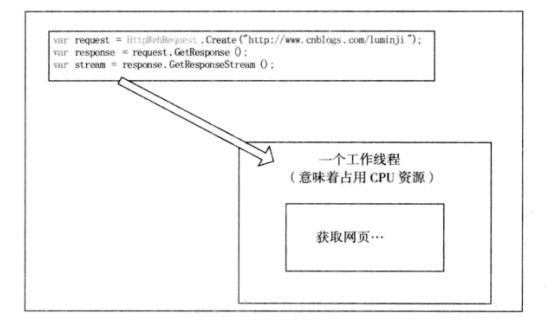
为了获取网页,CLR新起了一个工作线程,然后在读取网页的整个过程中,该工作线程始终被阻滯,直到获取网页完毕为止。在整个过程中,工作线程被占用着,这意味着系统的资源始终被消耗着、等待着。如果我们修改一下代码,使用异步模式去实现,代码如下所示:
private void buttonGetPage_Click(object sender, EventArgs e)
{
var request = HttpWebRequest.Create("http://www.sina.com.cn");
request.BeginGetResponse(this.AsyncCallbackImpl, request);
}
public void AsyncCallbackImpl(IAsyncResult ar)
{
WebRequest request = ar.AsyncState as WebRequest;
var response = request.EndGetResponse(ar);
var stream = response.GetResponseStream();
using (StreamReader reader = new StreamReader(stream))
{
var content = reader.ReadLine();
//textBoxPage.Text = content;
if (textBoxPage.InvokeRequired)
textBoxPage.BeginInvoke(new Action(() =>
{
textBoxPage.Text = content;
}));
else
textBoxPage.Text = content;
}
}

经过修改的示例采用了异步模式,它使用线程池进行管理。新起异步操作后,CLR会将工作丢给线程池中的某个工作线程来完成。当开始I/O操作的时候,异步会将工作线程还给线程池,这时候就相当于获取网页的这个工作不会再占用任何CPU资源了。直到异步完成,即获取网页完毕,异步才会通过回调的方式通知线程池,让CLR响应异步完毕。可见,异步模式借助于线程池,极大地节约了CPU的资源。
明白了异步和多线程的区别后,我们来确定两者的应用场景:
- 计算密集型工作, 采用多线程
- IO密集型工作, 采用异步机制
建议72 : 在线程同步中使用信号量
所谓线程同步,就是多个线程在某个对象.上执行等待(也可理解为锁定该对象),直到该对象被解除锁定。C#中对象的类型分为引用类型和值类型。CLR在这两种类型上的等待是不一样的。我们可以简单地理解为在CLR中,值类型是不能被锁定的,即不能在一个值类型对象上执行等待。而在引用类型上的等待机制,又分为两类:锁定和信号同步。
锁定使用关键字lock和类型Monitor。两者没有实质区别,前者其实是后者的语法糖。这是最常用的同步技术。
本建议主要讨论信号同步。信号同步机制中涉及的类型都继承自抽象类WaitHandle,这些类型有EventWaitHandle (类型化为AutoResetEvent、ManualResetEvent)、 Semaphore以及Mutex。见类图6-3。
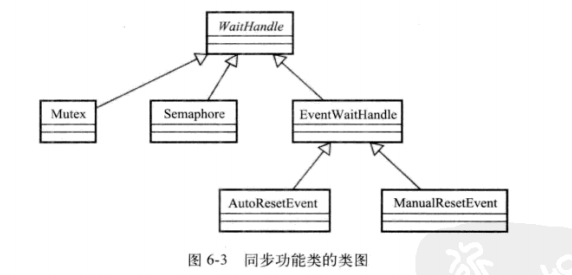
EventWaitHandle (子类为AutoResetEvent、ManualResetEvent)、 Semaphore以 及Mutex都继承自WaitHandle,所以它们底层的原理是一致的,维护的都是一个系统内核句柄。不过我们仍需简单地区分这三个类的类型。
EventWaitHandle维护一个由内核产生的布尔类型对象(称为“阻滞状态”),如果其值为false,那么在它上面等待的线程就阻塞。可以调用类型的Set方法将其值设置为true,解除阻塞。EventWaitHandle 类型有两个子类AutoResetEvent和ManualResetEvent,它们的区别并不大,本建议接下来会针对它们阐述如何正确使用信号量。
Semaphore维护一个由内核产生的整型变量,如果其值为0,则在它上面等待的线程就会阻塞:如果其值大于0,则解除阻塞,同时,每解除一个线程阻塞,其值就减1。
EventWaitHandle和Semaphore提供的都是单应用程序域内的线程同步功能,Mutex则不同,它为我们提供了跨应用程序域阻塞和解除阻塞线程的能力。
// 创建了一个同步类型对象, 设置自己的默认阻滞状态是false
// 这意味着任何在它上面进行等待的线程都将被阻滞
AutoResetEvent autoResetEvent = new AutoResetEvent(false);
// 此按钮负责开启一个线程
private void buttonStartAThread_Click(object sender, EventArgs e)
{
Thread tWork = new Thread(() =>
{
label1.Text = "线程启动..." + Environment.NewLine;
label1.Text += "开始处理一些实际的工作" + Environment.NewLine;
// 省略工作代码
label1.Text += "我开始等待别的线程给我信号,才愿意继续下去" + Environment.NewLine;
// 开始等待, 等待信号,
autoResetEvent.WaitOne();
label1.Text += "我继续做一些工作,然后结束了!";
// 省略工作代码
});
tWork.IsBackground = true;
tWork.Start();
}
// 此按钮负责给刚开启的线程发送信号
private void buttonSet_Click(object sender, EventArgs e)
{
// 给在autoResetEvent上等待的线程一个信号
// 将阻滞状态设为true, 上述线程收到信号后开始继续工作
autoResetEvent.Set();
}
AutoResetEvent和ManualResetEvent的区别是:前者在发送信号完毕后(即调用Set方法),会自动将自己的阻滞状态设置为false,而后者则需要进行手动设定。通过一个例子来说明这种区别,如下所示:
AutoResetEvent autoResetEvent = new AutoResetEvent(false);
private void buttonStartAThread_Click(object sender, EventArgs e)
{
StartThread1();
StartThread2();
}
private void StartThread1()
{
Thread tWork1 = new Thread(() =>
{
label1.Text = "线程1启动..." + Environment.NewLine;
label1.Text += "开始处理一些实际的工作" + Environment.NewLine;
//省略工作代码
label1.Text += "我开始等待别的线程给我信号,才愿意继续下去" + Environment.NewLine;
autoResetEvent.WaitOne();
label1.Text += "我继续做一些工作,然后结束了!";
//省略工作代码
});
tWork1.IsBackground = true;
tWork1.Start();
}
private void StartThread2()
{
Thread tWork2 = new Thread(() =>
{
label2.Text = "线程2启动..." + Environment.NewLine;
label2.Text += "开始处理一些实际的工作" + Environment.NewLine;
//省略工作代码
label2.Text += "我开始等待别的线程给我信号,才愿意继续下去" + Environment.NewLine;
autoResetEvent.WaitOne();
label2.Text += "我继续做一些工作,然后结束了!";
//省略工作代码
});
tWork2.IsBackground = true;
tWork2.Start();
}
private void buttonSet_Click(object sender, EventArgs e)
{
//给在autoResetEvent上等待的线程一个信号
autoResetEvent.Set();
}
这个例子的本意是要让新起的两个工作线程tWork1和tWork2都阻滞,直到收到主线程的信号再继续工作。而程序运行的结果是,只有一个工作线程继续工作,另外一个工作线程则继续保持阻滞状态。我想可能大家都已经猜到原因了,即AutoResetEvent发送信号完毕就在内核中自动将自己的状态设置回false了,所以另外一个工作线程相当于根本没有收到主线程的信号。要修正这个问题,可以使用ManualResetEvent。
最后,再举一个需要用到线程同步的实际例子:模拟网络通信。客户端在运行过程中,服务器每隔一段的时间会给客户端发送心跳数据。实际工作中的服务器和客户端在网络中是两台不同的终端,不过在这个例子中我们将其进行了简化:工作线程tClient模拟客户端,主线程(UI线程)模拟服务器端。客户端每3秒检测是否收到服务器的心跳数据,如果没有心跳数据,则显示网络连接断开。代码如下所示:
Thread tClient = new Thread(() =>
{
while (true)
{
//等3秒,3秒没有信号,显示断开
//有信号,则显示更新
bool re = autoResetEvent.WaitOne(3000);
if (re)
{
label1.Text = string.Format("时间:{0},{1}", DateTime.Now.ToString(), "保持连接状态");
}
else
{
label1.Text = string.Format("时间:{0},{1}", DateTime.Now.ToString(), "断开,需要重启");
}
}
});
tClient.IsBackground = true;
tClient.Start();
建议73 : 避免锁定不恰当的同步对象
在C#中,让线程同步的另一种编码方式就是使用线程锁。线程锁的原理,就是锁住一个资源,使得应用程序在此刻只有一个线程访问该资源。通俗地讲,就是让多线程变成单线程。在C#中,可以将被锁定的资源理解成new出来的普通CLR对象。既然需要锁定的资源就是C#中的一个对象,我们就该仔细思考,到底什么样的对象能够成为一个锁对象(也叫同步对象)?在选择同步对象的时候,应当始终注意以下几点:
- 1)同步对象在需要同步的多个线程中是可见的同一个对象。
- 2)在非静态方法中,静态变量不应作为同步对象。
- 3)值类型对象不能作为同步对象。
- 4)避免将字符串作为同步对象。
- 5)降低同步对象的可见性。
第一个注意事项:需要锁定的对象在多个线程中是可见的,而且是同一个对象。“可见的”这是显而易见的,如果对象不可见,就不能被锁定。“同一个对象”,这也很容易理解,如果锁定的不是同一个对象,那又如何来同步两个对象呢?虽然理解起来简单,但不见得我们在这上面就不会犯错误。
为了帮助大家理解本建议的内容,我们先模拟一个必须使用到锁的场景:在遍历一个集合的过程中,同时在另外一个线程中删除集合中的某项。下面这个例子中,如果没有lock语句,将会抛出异常InvalidOperationException :“集合已修改:可能无法执行枚举”;
AutoResetEvent autoSet = new AutoResetEvent(false);
List<string> tempList = new List<string>() { "init0", "init1", "init2" };
private void buttonStartThreads_Click(object sender, EventArgs e)
{
object syncObj = new object();
Thread t1 = new Thread(() =>
{
//确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
lock (syncObj)
{
foreach (var item in tempList)
{
Thread.Sleep(1000);
}
}
});
t1.IsBackground = true;
t1.Start();
Thread t2 = new Thread(() =>
{
//通知t1可以执行代码
autoSet.Set();
//沉睡1秒是为了确保删除操作在t1的迭代过程中
Thread.Sleep(1000);
lock (syncObj)
{
tempList.RemoveAt(1);
}
});
t2.IsBackground = true;
t2.Start();
}
这是一个Winform窗体应用程序,需要演示的功能在按钮的单击事件中。对象syncObj对于线程t1和12来说,在CLR中肯定是同一个对象。所以,上面的示例运行是没有问题的。
现在,我们将此示例重构。将实际的工作代码移到一个类型SampleClass中,该示例要在多个SampleClass实例间操作一个静态字段,如下所示:
private void buttonStartThreads_Click(object sender, EventArgs e)
{
SampleClass sample1 = new SampleClass();
SampleClass sample2 = new SampleClass();
sample1.StartT1();
sample2.StartT2();
}
class SampleClass
{
public static List<string> TempList = new List<string>() { "init0", "init1", "init2" };
static AutoResetEvent autoSet = new AutoResetEvent(false);
object syncObj = new object();
public void StartT1()
{
Thread t1 = new Thread(() =>
{
//确保等待t2开始之后才运行下面的代码
autoSet.WaitOne();
lock (syncObj)
{
foreach (var item in TempList)
{
Thread.Sleep(1000);
}
}
});
t1.IsBackground = true;
t1.Start();
}
public void StartT2()
{
Thread t2 = new Thread(() =>
{
//通知t1可以执行代码
autoSet.Set();
//沉睡1秒是为了确保删除操作在t1的迭代过程中
Thread.Sleep(1000);
lock (syncObj)
{
TempList.RemoveAt(1);
}
});
t2.IsBackground = true;
t2.Start();
}
}
该示例运行起来会抛出异常InvalidOperationException:“集合已修改:可能无法执行枚举。”
查看类型SampleClass的方法StartT1和StartT2,方法内部锁定的是SampleClass的实例变量syncObject。实例变量意味着,每创建一个SampleClass的实例都会生成一个syncObject对象。在本例中,调用者一共创建了两个SampleClass实例,继而分别调用:sample1.StartT1(); samp1e2. .StartT2();
也就是说,以上代码锁定的是两个不同的syncObject,这等于完全没有达到两个线程锁定同一个对象的目的。要修正以上错误,只要将syncObject变成static 就可以了。
另外,思考一下lock(this),我们同样不建议在代码中编写这样的代码。如果两个对象的实例分别执行了锁定的代码,实际锁定的也就会是两个对象,完全不能达到同步的目的。
- 第二个注意事项: 在非静态方法中,静态变量不应作为同步对象。也许有读者会问,前面曾说到,要修正第一个注意事项中的示例问题,需要将syncObject变成static.这似乎和本注意事项有矛盾。事实上,第一个注意事项中的示例代码仅仅出于演示的目的,在实际应用中,我们强烈建议不要编写此类代码。在编写多线程代码时,要遵循这样的一个原则:
类型的静态方法应当保证线程安全,非静态方法不需实现线程安全。
FCL中的绝大部分类都遵循了这个原则。像上一个示例中,如果将syncObject变成static,就相当于让非静态方法具备了线程安全性,这带来的一个问题是,如果应用程序中该类型存在多个实例,在遇到这个锁的时候,它们都会产生同步,而这可能不是开发者所愿意看到的。第二个注意事项实际也可以归纳到第一个注意事项中。
第三个注意事项: 值类型对象不能作为同步对象。值类型在传递到另一个线程的时候,会创建一个副本,这相当于每个线程锁定的也是两个对象。因此,值类型对象不能作为同步对象。
第四个注意事项: 锁定字符串是完全没有必要的,而且相当危险。这整个过程看上去和值类型正好相反。字符串在CLR中会被暂存到内存里,如果有两个变量被分配了相同内容的字符串,那么这两个引用会被指向同一块内存。 所以,如果有两个地方同时使用了lock(“abc” ),那么它们实际锁定的是同一个对象,这会导致整个应用程序被阻滞。
第五个注意事项: 降低同步对象的可见性。可见范围最广的一种同步对象是typeof(SampleClass)。 typeof 方法所返回的结果(也就是类型的type)是SampleClass的所有实例所共有的,即:所有实例的type都指向typeof方法的结果。这样一来,如果我们lock(typeof(SampleClass)),当前应用程序中所有SampleClass的实例线程将会全部被同步。这样编码完全没有必要,而且这样的同步对象太开放了。
一般来说,同步对象也不应该是一个公共变量或属性。在FCL的早期版本中,一些常用的集合类型(如ArrayList)提供了公共属性SyncRoot,让我们锁定以便进行一些线程安全的操作。所以你一定会觉得我们刚才的结论不正确。其实不然,ArrayList 操作的大部分应用场景不涉及多线程同步,所以它的方法更多的是单线程应用场景。线程同步是一个非常耗时(低效)的操作。若ArrayList的所有非静态方法都要考虑线程安全,那么ArrayList完全可以将这个SyncRoot变成静态私有的。现在它将SyncRoot变为公开的,是让调用者自己去决定操作是否需要线程安全。我们在编写代码时,除非有这样的要求,否则就应该始终考虑降低同步对象的可见性,将同步对象藏起来,只开放给自己或自己的子类就够了(需要开放给子类的情况其实也不多)。
建议74 : 警惕线程的IsBackground
在CLR中,线程分为前台线程和后台线程,即每个线程都有一个IsBackground属性。两者在表现形式上的唯一区别是:如果前台线程不退出,应用程序的进程就会一直存在,必须所有的前台线程全部退出,应用程序才算退出。而后台进程则没有这方面的限制,如果应用程序退出,后台线程也会一并退出。
static void Main(string[] args)
{
Thread t = new Thread(() =>
{
Console.ReadKey();
Console.WriteLine("线程结束");
});
//注意,默认就为false
t.IsBackground = false;
t.Start();
Console.WriteLine("主线程完毕");
}
用Thread创建的线程默认是前台线程,也就是IsBackground 属性默认是false. 以上代码需等到工作结束(敲入一个按键)应用程序才会结束,而如果设置IsBackground为true,应用程序则会立刻结束。
演示代码使用的是Thread,但我们要注意 线程池中的线程默认都是后台线程。基于前后台线程的区别,在实际编码中应该更多地使用后台线程。只有在非常关键的工作中,如线程正在执行事务或占有的某些非托管资源需要释放时,才使用前台线程。
建议75 : 警惕线程不会立即启动
现代的大多数操作系统都不是一个实时的操作系统,Windows系统也是如此。所以,不能奢望我们的线程能够立即启动。Windows内部会实现特殊的算法以进行线程之间的调度,在某个具体的时刻,它会决定当前应该运行哪个线程。这反映到最底层就是某个线程分配到了一定的CPU时间,可用来执行一小段工作(由于被分配的CPU时间很短,所以即使操作系统中运行了上千个线程,我们也会觉得这些应用程序是在同时执行的)。Windows会选择在适当的时间根据自己的算法决定下一段的CPU时间如何调度。
线程的调度是一个复杂的过程,对于C#开发者来说,需要理解的就是: 线程之间的调度占有一定的时间和空间开销,并且,它不实时。下面是一个测试的例子,本意是将0到9分别传给10个不同的线程,结果却事与愿违:
static int _id = 0;
static void Main()
{
for (int i = 0; i < 10; i++, _id++)
{
Thread t = new Thread(() =>
{
Console.WriteLine(string.Format("{0}:{1}", Thread.CurrentThread.Name, _id));
});
// 给线程一个名称
t.Name = string.Format("Thread{0}", i);
t.IsBackground = true;
t.Start();
}
Console.ReadLine();
}
// Thread0:1
// Thread2:3
// Thread1:2
// Thread5:6
// Thread6:7
// Thread3:4
// Thread7:8
// Thread8:9
// Thread9:10
// Thread4:5
这段代码的输出从两个方面印证了线程不是立即启动的。首先,我们看到线程并没有按照顺序启动。在代码逻辑中,前面Start的那个线程也许迟于后Start的那个线程执行。其次,传入线程内部的ID值,不再是for循环执行中当前的ID值。以Thread9为例,在for循环中,其当前的值为9,而Thread9真正得到执行的时候,ID却已经跳出循环,早已经变为10了。
要让需求得到正确的编码,需要把上面的for循环修改成为一段同步代码:
static int _id = 0;
static void Main()
{
for (int i = 0; i < 10; i++, _id++)
{
NewMethod1(i, _id);
}
Console.ReadLine();
}
private static void NewMethod1(int i, int realTimeID)
{
Thread t = new Thread(() =>
{
Console.WriteLine(string.Format("{0}:{1}", Thread.CurrentThread.Name, realTimeID));
});
t.Name = string.Format("Thread{0}", i);
t.IsBackground = true;
t.Start();
}
// Thread0:0
// Thread3:3
// Thread6:6
// Thread7:7
// Thread8:8
// Thread9:9
// Thread4:4
// Thread1:1
// Thread2:2
// Thread5:5
可以看到,线程虽然保持了不会立即启动的特点,但是传入线程的ID值,由于在for循环内部变成了同步代码,所以能够正确传入。
建议76 : 警惕线程的优先级
线程在C#中有5个优先级: Highest. AboveNormal、 Normal, BelowNormal 和Lowest。讲到线程的优先级,就会涉及线程的调度。Windows 系统是一个基于优先级的抢占式调度系统。在系统中,如果有一个线程的优先级较高,并且它正好处在就绪状态,系统总是会优先运行该线程。换句话说,高优先级的线程总是在系统调度算法中获取更多的CPU执行时间.
t1.Priority = ThreadPriority.Highest;
在C#中,使用Thread和ThreadPool新起的线程,默认优先级都是Normal。虽然可以像上面的示例那样去修改线程的优先级,但是一般不建议这样做。当然,如果是一些非常关键的线程,我们还是可以提升线程的优先级的。这些关键线程应当具有运行时间短、能即刻进入等待状态等特征。
建议77 : 正确停止线程
开发者总尝试对自己的代码有更多的控制。例如,“让那个还在工作的线程马上停止下来”。然而,并非我们想怎样就可以怎样的,这至少涉及两个问题。
第一个问题正如线程不能立即启动一样,线程也并不是说停就停的。无论采用何种方式通知工作线程需要停止,工作线程都会忙完手头最紧要的活,然后在它觉得合适的时候退出。以最传统的Thread.Abort方法为例,如果线程当前正在执行的是一段非托管代码,那么CLR就不会抛出ThreadAbortException,只有当代码继续回到CLR中时,才会引发ThreadAbortException。当然,即便是在CLR环境中,ThreadAbortException也不会立即引发。
第二个问题要正确停止线程, 不在于调用者采取了什么行为(如最开始的Thread.Abort()方法),而更多依赖于工作线程是否能主动响应调用者的停止请求。大体机制是,如果线程需要被停止,那么线程自身就应该负责给调用者开放这样的接口: Cancled。 线程在工作的同时,还要以某种频率检测Cancled标识,若检测到Cancled,线程自己才会负责退出。
FCL现在为我们提供了标准的取消模式:协作式取消(Cooperative Cancellation)。协作式取消的机制就是上文第二个问题中所提到的机制。下面是一个最基础的协作式取消的示例:
CancellationTokenSource cts = new CancellationTokenSource();
Thread t = new Thread(() =>
{
while (true)
{
if (cts.Token.IsCancellationRequested)
{
Console.WriteLine("线程被终止!");
break;
}
Console.WriteLine(DateTime.Now.ToString());
Thread.Sleep(1000);
}
});
t.Start();
Console.ReadLine();
cts.Cancel();
调用者使用CancellationTokenSource的Cancel方法通知工作线程退出。工作线程则以大约1000ms的频率一边 工作,一边检查是否有外界传人的Cancel信号,若有这样的信号,则退出。可以看到,在正确停止线程的机制中,真正起到主要作用的是线程本身。示例中的工作代码比较简单,但足以说明问题。更复杂的计算式工作,也应该以这样的一种方式, 妥善而正确地处理退出。
协作式取消中的关键类型是CancellationTokenSource.它有一个关键属性Token,Token是一个名为CancellationToken的值类型。CancellationToken 继而进一步提供了布尔值的属性IsCancellationRequested作为需要取消工作的标识。CancellationToken 还有一个方法尤其值得注意,那就是Register方法。它负责传递一个Action委托,在线程停止的时候被回调,使用方法如下:
cts.Token.Register(() =>
{
Console.WriteLine("工作线程被终止了");
});
后面还会讲到任务Task,它依赖于CancellationTokenSource和CancellationToken完成了所有的取消控制。
建议78 : 应避免线程数量过多
在多数情况下,创建过多的线程意味着应用程序的架构设计可能存在着缺陷。经常有人会问,一个应用程序中到底含有多少线程才是合理的。现在我们找一台PC机,打开Windows的任务管理器,看看操作系统中正在运行的程序有多少个线程。在笔者当前的PC机上,线程数最多的一个应用程序是某款杀毒软件,它一共拥有116个线程数:其次是Windows自身的System进程,当前共有104个线程:第三多的进程是Sqlservr.exe,锐减到了35个线程:剩下还有63个进程,估计它们平均约有10个线程。所以说,大多数应用程序的线程数不会太多。
错误地创建过多线程的一个典型的例子是:为每一个Socket 连接建立一个线程去管理。每个连接一个线程,意味着在32位系统的服务器不能同时管理超过1000台的客户机。CLR为每个进程分配的内存会超过1MB。约1000个进程,加上.NET进程启动本身所占用的一些内存,即刻就耗尽了系统能分配给进程的最大可用地址空间2GB。即便应用程序在设计之初的需求设计书中说明,生产环境中客户端数目不会超过500台,在管理这500台客户端时进行线程上下文切换,也会损耗相当多的CPU时间。这类I/O密集型场合应该使用异步去完成(请参考建议71的相关阐述)。
过多的线程还会带来另外的问题:新起的线程可能需要等待相当长的时间才会真正运行。这是一个相当无奈的结果,在多数情况下,我们都不能忍受等待这么长时间。
除了启动问题外,线程之间的切换也存在同样的问题,下一次执行,还会等待相当长的时间。所以,不要滥用线程,尤其不要滥用过多的线程。当新起线程的时候,需要仔细思考这项工作是否真的需要新起线程去完成。即使真的需要线程也应该考虑使用线程池技术。例如本建议所提到的Socket连接这样的I/O密集型场合,应当始终考虑使用异步来完成。异步会在后台使用线程池进行管理。1000 台客户端在使用了异步技术后,实际只要几个线程就能完成所有的管理工作(具体取决于“心跳频率”)。
建议79 : 使用ThreadPool或BackgroundWorker代替Thread
使用线程能极大地提升用户体验度,但是作为开发者应该注意到,线程的开销是很大的。
线程的空间开销来自:
- 1)
线程内核对象(Thread Kermel Object)。- 每个线程都会创建一个这样的对象,它主要包含线程上下文信息,在32位系统中,它所占用的内存在700字节左右。
- 2)
线程环境块(Thread Environment Block)。- TEB包括线程的异常处理链,32位系统中占用4KB内存。
- 3)
用户模式栈(User Mode Stack),即线程栈。- 线程栈用于保存方法的参数、局部变量和返回值。每个线程栈占用1024KB的内存。要用完这些内存很简单,写一个不能结束的递归方法,让方法参数和返回值不停地消耗内存,很快就会发生OutOfMemoryException。
- 4)
内核模式栈(Kernel Mode Stack)。- 当调用操作系统的内核模式函数时,系统会将函数参数从用户模式栈复制到内核模式栈。在32位系统中,内核模式栈会占用12KB内存。
线程的时间开销来自:
- 1)线程创建的时候,系统相继初始化以上这些内存空间。
- 2)接着CLR会调用所有加载DLL的DLLMain方法,并传递连接标志(线程终止的时候,也会调用DLL的DLLMain方法,并传递分离标志)。
- 3)线程上下文切换。
- 一个系统中会加载很多的进程,而一个进程又包含若干个线程。但是一个CPU在任何时候都只能有一个线程在执行。
为了让每个线程看上去都在运行,系统会不断地切换“线程上下文”:每个线程大概得到几十毫秒的执行时间片,然后就会切换到下一个线程了。这个过程大概又分为以下5个步骤:
- 步骤1进入内核模式。
- 步骤2将上下文信息 (主要是一些CPU寄存器信息)保存到正在执行的线程内核对象上。
- 步骤3系统获取 一个Spinlock, 并确定下一个要执行的线程,然后释放Spinlock.
- 如果下一个线程不在同一个进程内,则需要进行虚拟地址交换。
- 步骤4从将 被执行的线程内核对象上载入上下文信息。
- 步骤5离开内核模式。
由于要进行如此多的工作,所以创建和销毁一-个线 程就意味着代价“昂贵”。为了避免程序员无节制地使用线程,微软开发了“线程池”技术。简单来说,线程池就是替开发人员管理工作线程。当一项工作完毕时,CLR不会销毁这个线程,而是会保留这个线程一段时间,看是否有别的工作需要这个线程。至于何时销毁或新起线程,由CLR根据自身的算法来做这个决定。所以,如果我们要多线程编码,不应想到直接new Thread, 而是首先想到:
ThreadPool.QueueUserWorkItem((objState) =>
{
//...
},null);
建议80 : 用Task代替ThreadPool
ThreadPool相对于Thread来说具有很多优势,但是ThreadPool在使用上却存在一定的不方便。比如:
- ThreadPool不支持线程的取消、完成、失败通知等交互性操作。
- ThreadPool不支持线程执行的先后次序。
以往,如果开发者要实现上述功能,需要完成很多额外的工作。现在,FCL中提供了一个功能更强大的概念: Task。 Task 在线程池的基础上进行了优化,并提供了更多的API。在FCL4.0中,如果我们要编写多线程程序,Task 显然已经优于传统的方式了。以下是一个简单的任务示例:
static void Main(string[] args)
{
Task t = new Task(() =>
{
Console.WriteLine("任务开始工作……");
//模拟工作过程
Thread.Sleep(5000);
});
t.Start();
t.ContinueWith((task) =>
{
Console.WriteLine("任务完成,完成时候的状态为:");
Console.WriteLine("IsCanceled={0}\tIsCompleted={1}\tIsFaulted={2}", task.IsCanceled, task.IsCompleted, task.IsFaulted);
});
Console.ReadKey();
}
任务Task具备以下属性,可以让我们查询任务完成时的状态:
- IsCanceled 因为被取消而完成
- IsCompleted 成功完成
- IsFaulted 因为发生异常而完成
需要注意的是,任务并没有提供回调事件来通知完成(像BackgroundWorker一样),它是通过启用一个新任务的方式来完成类似的功能。ContinueWith 方法可以在一个任务完成的时候发起一个新任务,这种方式天然就支持了任务的完成通知:我们可以在新任务中获取原任务的结果值。
下面是一个稍微复杂的例子,同时支持完成通知、取消、获取任务返回值等功能:
static void Main(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
// 任务结果返回一个int
Task<int> t = new Task<int>(() => Add(cts.Token), cts.Token);
t.Start();
t.ContinueWith(TaskEnded);
//等待按下任意一个键取消任务
Console.ReadKey();
cts.Cancel();
Console.ReadKey();
}
static void TaskEnded(Task<int> task)
{
Console.WriteLine("任务完成,完成时候的状态为:");
Console.WriteLine("IsCanceled={0}\tIsCompleted={1}\tIsFaulted={2}", task.IsCanceled, task.IsCompleted, task.IsFaulted);
Console.WriteLine("任务的返回值为:{0}", task.Result);
}
// 需要传入取消令牌对象CancellationToken
static int Add(CancellationToken ct)
{
Console.WriteLine("任务开始……");
int result = 0;
// 判断是否取消
while (!ct.IsCancellationRequested)
{
result++;
Thread.Sleep(1000);
}
return result;
}
// 在任务开始后大概3秒的时候按下键盘,会得到如下的输出:
//任务开始……
//任务完成,完成时候的状态为:
//IsCanceled=False IsCompleted=True IsFaulted=False
//任务的返回值为:3
你也许会奇怪,我们的任务是通过Cancel的方式处理的,为什么完成的状态IsCanceled那一栏还是 False。因为在工作任务中,我们对IsCancellationRequested进行了业务逻辑上的处理,但是并没有通过ThrowlfCancellationRequested方法来处理。
如果采用ThrowIfCancellationRequested方法,则代码应如下所示:
static void TaskEndedByCatch(Task<int> task)
{
Console.WriteLine("任务完成,完成时候的状态为:");
Console.WriteLine("IsCanceled={0}\tIsCompleted={1}\tIsFaulted={2}", task.IsCanceled, task.IsCompleted, task.IsFaulted);
try
{
Console.WriteLine("任务的返回值为:{0}", task.Result);
}
catch (AggregateException e)
{
e.Handle((err) => err is OperationCanceledException);
}
}
static int AddCancleByThrow(CancellationToken ct)
{
Console.WriteLine("任务开始……");
int result = 0;
while (true)
{
ct.ThrowIfCancellationRequested();
result++;
Thread.Sleep(1000);
}
return result;
}
在任务结束求值的方法TaskEndedByCatch中,如果任务是通过ThrowfCancellationRequested方法结束的,对任务求结果值将会抛出异常OperationCanceledException,而不是得到抛出异常前的结果值。这意味着任务是通过异常的方式被取消掉的,所以可以注意到上面代码的输出中,状态IsCanceled 为True.
接着来看上面的输出,我们注意到取消是通过异常的方式实现的,而表示任务中发生了异常的IsFaulted状态却还是为False,为什么呢?这是因为ThrowIfCancellationRequested是协作式取消方式的类型CancellationTokenSource中的一个方法,CLR对其进行了特殊的处理。CLR知道这一行程序是开发者有意为之,所以不把它看做是一个异常(它被理解为取消)。要得到IsFaulted等于True的状态,我们可以修改While循环,模拟一个异常出来,具体方法如下:
while (true)
{
// ct.ThrowIfCancellationRequested();
if(result == 5)
{
throw new Exception("error");
}
result++;
Thread.Sleep(1000);
}
// 在任务开始后大概3秒的时候按下键盘,会得到如下的输出:
//任务开始……
//任务完成,完成时候的状态为:
//IsCanceled=False IsCompleted=True IsFaulted=True
//任务的返回值为:3
Task还支持任务工厂的概念。任务工厂支持多个任务之间共享相同的状态,如取消类型CancellationTokenSource就是可以被共享的。通过使用任务工厂,可以同时取消一组任务.
static void Main(string[] args)
{
CancellationTokenSource cts = new CancellationTokenSource();
//等待按下任意一个键取消任务
TaskFactory taskFactory = new TaskFactory();
Task[] tasks = new Task[]
{
taskFactory.StartNew(() => Add(cts.Token)),
taskFactory.StartNew(() => Add(cts.Token)),
taskFactory.StartNew(() => Add(cts.Token))
};
//CancellationToken.None指示TasksEnded不能被取消
taskFactory.ContinueWhenAll(tasks, TasksEnded, CancellationToken.None);
Console.ReadKey();
cts.Cancel();
Console.ReadKey();
}
static void TasksEnded(Task[] tasks)
{
Console.WriteLine("所有任务已完成!");
}
本建议演示了Task (任务)和TaskFactory (任务工厂)的使用方法。Task进一步优化了后台线程池的调度,加快了线程的处理速度。所以在FCL 4.0时代,如果要使用多线程,我们理应更多地使用Task。
建议81 : 使用Parallel简化同步状态下Task的使用
在命名空间System.Threading.Tasks中,有一个静态类Parallel简化了在同步状态下的Task的操作。Parallel 主要提供3个有用的方法: For、 ForEach、 Invoke。
For方法主要用于处理针对数组元素的并行操作:
static void Main(string[] args)
{
int[] nums = new int[] { 1, 2, 3, 4 };
Parallel.For(0, nums.Length, (i) =>
{
Console.WriteLine("针对数组索引{0}对应的那个元素{1}的一些工作代码……", i, nums[i]);
});
Console.ReadKey();
}
// 针对数组索引3对应的那个元素4的一些工作代码……
// 针对数组索引1对应的那个元素2的一些工作代码……
// 针对数组索引0对应的那个元素1的一些工作代码……
// 针对数组索引2对应的那个元素3的一些工作代码……
可以看到,工作代码并未按照数组的索引次序进行遍历。这是因为我们的遍历是并行的,不是顺序的。所以,这里也可以引出一个小建议:如果我们的输出必须是同步的或者说必须是顺序输出的,则不应使用Parallel的方式。ForEach方法主要用于处理泛型集合元素的并行操作,如下所示:
static void Main(string[] args)
{
List<int> nums = new List<int> { 1, 2, 3, 4 };
Parallel.ForEach(nums, (item) =>
{
Console.WriteLine("针对集合元素{0}的一些工作代码……", item);
});
Console.ReadKey();
}
使用For和ForEach方法,Parallel 类型会自动为我们分配Task来完成针对元素的一些工作。当然我们也可以直接使用Task,但是上面的这种形式在语法上更为简洁。
Parallel的Invoke方法为我们简化了启动一组并行操作,它隐式启动的就是Task. 该方法接受Params Action[]参数,如下所示:
static void Main(string[] args)
{
Parallel.Invoke(
() =>
{
Console.WriteLine("任务1……");
},
() =>
{
Console.WriteLine("任务2……");
},
() =>
{
Console.WriteLine("任务3……");
});
Console.ReadKey();
}
同样,由于所有的任务都是并行的, 所以它不保证先后次序.
建议82 : Parallel 简化但不等同于Task默认行为
建议81说到了Parallel的使用方法,不知道大家是否注意到文中使用的字眼: 在同步状态下简化了Task的使用。也就是说,在运行Parallel中的For、ForEach 方法时,调用者线程(在示例中就是主线程)是被阻滞的。Parallel 虽然将任务交给Task去处理,即交给CLR线程池去处理,不过调用者会一直等到线程池中的相关工作全部完成。表示并行的静态类Parallel甚至只提供了Invoke方法,而没有同时提供一个BeginInvoke方法,这也从一定程度上说明了这个问题。
在使用Task时,我们最常使用的是Start方法(Task 也提供了RunSynchronously),它不会阻滞调用者线程。如下所示:
// Task不会阻滞线程, 会输出主线程即将结束
static void Main()
{
Task t = new Task(() =>
{
while (true)
{
}
});
t.Start();
Console.WriteLine("主线程即将结束");
Console.ReadKey();
}
// 这段代码永远也不会有输出, 因为主线程被阻滞
static void Main()
{
//在这里也可以使用Invoke方法
Parallel.For(0, 1, (i) =>
{
while (true)
{
}
});
Console.WriteLine("主线程即将结束");
Console.ReadKey();
}
并行编程,意味着运行时在后台将任务分配到尽量多的CPU上,虽然它在后台使用Task进行管理,但这并不意味着它等同于异步。
建议83 : 小心Parallel中的陷阱
Parallel的For和ForEach方法还支持一些相对复杂的应用。在这些应用中,它允许我们在每个任务启动时执行一些初始化操作,在每个任务结束后,又执行一些后续工作,同时,还允许我们监视任务的状态。但是,记住上面这句话“允许我们监视任务的状态”是错误的 : 应该把其中的“任务”改成“线程”。这,就是陷阱所在。
我们需要深刻理解这些具体的操作和应用,不然,极有可能陷入这个陷阱中去。下面体会这段代码的输出是什么,如下所示:
static void Main(string[] args)
{
int[] nums = new int[] {1, 2, 3, 4};
int total = 0;
Parallel.For<int>(
0, // 参数1: 起始索引
nums.Length, // 参数2: 结束索引
() => { return 1; },// 参数3: Func<TLocal>,用于新起线程初始化任务体subtotal的值
(i, loopState, subtotal) =>
{
subtotal += nums[i];
return subtotal;
}, // 参数4: 任务体本身Func<int, ParallelLoopState, TLocal, TLocal>
(x) => Interlocked.Add(ref total, x) //参数5: Action<TLocal> localFinally, 用于线程结束时的收尾工作total += subtotal;
);
Console.WriteLine("total={0}", total);
Console.ReadKey();
}
// public static ParallelLoopResult For<TLocal>(
// int fromInclusive, int toExclusive,
// Func<TLocal> localInit,
// Func<int, ParallelLoopState, TLocal, TLocal> body,
// Action<TLocal> localFinally)
这段代码有可能输出11,较少的情况下输出12,虽然理论上有可能输出13和14,但是我们应该很少有机会观察到。要明白为什么会有这样的输出,首先必须详细了解For方法的各个参数。
前面两个参数相对容易理解,分别是起始索引和结束索引。参数body也比较容易理解,即任务体本身。其中subtotal 为单个任务的返回值。locallnit和localFinally就比较难理解了,并且陷阱也在这里。要理解这两个参数,必须先理解Parallel.For方法的运作模式。
For方法采用并发的方式来启动循环体中的每个任务,这意味着,任务是交给线程池去管理的。在上面的代码中,循环次数共计4次, 实际运行时调度启动的后台线程也就只有一个或两个。这就是并发的优势,也是线程池的优势,Parallel 通过内部的调度算法,最大化地节约了线程的消耗。
locallnit 的作用是如果Parallel为我们新起了一个线程,它就会执行一些初始化的任务在上面的例子中:() => { return 1; }, 它会将任务体的subtotal初始化为1.
localFinally的作用是,在每个线程结束的时候, 它执行一些收尾工作(x) => Interlocked.Add(ref total, x) 实际也就是 total = total + subtotal;其中的x,其实代表的就是任务体中的返回值,具体在这个例子中就是subtotal在返回时的值。使用Interlocked是对total使用原子操作,以避免并发所带来的问题。
现在,我们应该很好理解为什么上面这段代码的输出会不确定了。Parallel一共启动了4个任务,但是我们不能确定Parallel到底为我们启动了多少个线程,那是运行时根据自己的调度算法决定的。如果所有的并发任务只用了一个线程,则输出为11 ;如果用了两个线程,那么根据程序的逻辑来看,输出就是12了。
在这段代码中,如果让locallnit返回的值为0,也许你就永远不会注意到这个陷阱:() => { return 0; }
现在,为了更清晰地体会这个陷阱,我们使用下面这段更好理解的代码:
static void Main(string[] args)
{
string[] stringArr = new string[] { "aa", "bb", "cc", "dd", "ee", "ff", "gg", "hh" };
string result = string.Empty;
Parallel.For<string>(0, stringArr.Length, // 循环8次
() => "-", // 如果新起一个线程, 则执行这个初始化, 设置subResult的初始值为"-"
(i, loopState, subResult) =>
{
return subResult += stringArr[i];
}, // 任务主体
(threadEndString) => // 线程结束时进行一些收尾工作
{
result += threadEndString;
Console.WriteLine("Inner:" + threadEndString);
});
Console.WriteLine(result);
Console.ReadKey();
}
// 这段代码的一个可能的输出为:
//Inner:-aabbceddffgghh
//Inner:-ee
//- aabbccddf fgghh- ee
建议84 : 使用PLINQ
第2章已经介绍过LINQ. LINQ最基本的功能就是对集合进行遍历查询,并在此基础上对元素进行操作。仔细推敲会发现,并行编程简直就是专门为这一类应用准备的。因此,微软专门为LINQ拓展了一个类ParallelEnumerable (该类型也在命名空间System.Linq中),它所提供的扩展方法会让LINQ支持并行计算,这就是所谓的PLINQ。传统的LINQ计算是单线程的,PLINQ 则是并发的、多线程的,我们通过下面这个示例就可以看出这个区别:
List<int> intList = new List<int>() { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
var query = from p in intList select p;
Console.WriteLine("以下是LINQ顺序输出:");
foreach (int item in query)
{
Console.WriteLine(item.ToString());
}
Console.WriteLine("以下是PLINQ并行输出:");
var queryParallel = from p in intList.AsParallel() select p;
foreach (int item in queryParallel)
{
Console.WriteLine(item.ToString());
}
LINQ的输出会按照intList中的索引顺序打印出来。而PLINQ的输出是杂乱无章的。
并行输出还有另外一种方式可以处理,那就是对queryParallel求ForAll:
// 但是这种方法会带来一个问题,如果要将并行输出后的结果进行排序,ForAll会忽略掉查询的AsOrdered请求。
var queryParallel = from p in intList.AsParallel().AsOrdered() select p;
// ForAll会忽略掉查询的AsOrdered请求。
queryParallel.ForAll((item) =>
{
Console.WriteLine(item.ToString());
});
// 要保持AsOrdered方法的需求, 则需要使用如下方式
foreach (int item in queryParallel)
{
Console.WriteLine(item.ToString());
}
在并行查询后再进行排序,会牺牲掉一定的性能。一些扩展方法默认会对元素进行排序,这些方法包括: OrderBy、 OrderByDescending、 ThenBy 和ThenByDescending。在实际的使用中,一定要注意到各种方式之间的差别,以便程序按照我们的设想运行。
还有一些其他的查询方法,比如Take.如果我们这样编码:
foreach (int item in queryParallel.Take(5))
{
Console.WriteLine(item.ToString());
}
在顺序查询中,会返回前5个元素。但是在PLINQ中,会选出5个无序的元素。建议在对集合中的元素项进行操作的时候使用PLINQ代替LINQ。但是要记住,不是所有并行查询的速度都会比顺序查询快,在对集合执行某些方法时,顺序查询的速度会更快一点,如方法ElementAt等。在开发中,我们应该仔细辨别这方面的需求,以便找到最佳的解决方案。
建议85 : Task中的异常处理
在任何时候,异常处理都是非常重要的一个环节。多线程与并行编程中尤其是这样。如果不处理这些后台任务中的异常,应用程序将会莫名其妙的退出。处理那些不是主线程(如果是窗体程序,那就是UI主线程)产生的异常,最终的办法都是将其包装到主线程上。
在任务并行库中,如果对任务运行Wait、WaitAny、 WaitAll等方法,或者求Result属性,都能捕获到AggregateException异常。可以将AggregateException异常看做是任务并行库编程中最上层的异常。在任务中捕获的异常,最终都应该包装到AggregateException中。一个任务并行库异常的简单处理示例如下:
// 对于主工作任务采用Wait的方法,这是不可取的。因为主工作任务也许会持续一段较长的时间,那样会阻塞调用者
static void Main(string[] args)
{
Task t = new Task(() =>
{
throw new Exception("任务并行编码中产生的未知异常");
});
t.Start();
try
{
//若有Result,可求Result
t.Wait();
}
catch (AggregateException e)
{
foreach (var item in e.InnerExceptions)
{
Console.WriteLine("异常类型:{0}{1}来自于:{2}{3}异常内容:{4}", item.GetType(), Environment.NewLine, item.Source, Environment.NewLine, item.Message);
}
}
Console.WriteLine("主线程马上结束");
Console.ReadKey();
}
// 异常类型:System.Exception
// 来自于:Tip85
// 异常内容:任务并行编码中产生的未知异常
// 主线程马上结束
大家也许已经注意到,虽然运行Wait、WaitAny、 WaitAll 方法,或者求Result属性能得到任务的异常信息,但是这会阻滞当前线程。这往往不是我们所希望看到的,岂能为了得到一个异常就故意等待? 这时可以考虑任务并行库中Task类型的一个功能: 新起一个后续任务,就可以解决等待的问题:
// 虽然不阻塞主线程但是新任务只完成了处理异常,异常处理没有回到主线程中,它还是在线程池中
static void Main()
{
Task t = new Task(() =>
{
throw new Exception("任务并行编码中产生的未知异常");
});
t.Start();
Task tEnd = t.ContinueWith((task) =>
{
foreach (Exception item in task.Exception.InnerExceptions)
{
Console.WriteLine("异常类型:{0}{1}来自于:{2}{3}异常内容:{4}", item.GetType(), Environment.NewLine, item.Source, Environment.NewLine, item.Message);
}
}, TaskContinuationOptions.OnlyOnFaulted);
Console.WriteLine("主线程马上结束");
Console.ReadKey();
}
// 主线程马上结束
// 异常类型:System.Exception
// 来自于:Tip85
// 异常内容:任务并行编码中产生的未知异常
以上方法解决了主线程等待的问题,但是仔细研究我们会发现,异常处理没有回到主线程中,它还是在线程池中。在某些场合,比如对于业务逻辑上特定异常的处理,需要采取这种方式,而且我们也鼓励这种用法。但很明显,更多时候我们还需要更进一步将异常处理封装到主线程。
Task没有提供将任务中的异常包装到主线程的接口。一个可行的办法是,仍旧使用类似Wait的方法来达到此目的。在本建议一开始的代码中,我们对于主工作任务采用Wait的方法,这是不可取的。因为主工作任务也许会持续一段较长的时间,那样会阻塞调用者,并让调用者觉得不能忍受。而本建议的第二段代码中,新任务只完成了处理异常,这意味着新任务不会延续较长时间,所以,在这个新任务上维持等待对于调用者来说,是可以忍受的。所以,我们可以采用这个方法将异常包装到主线程中:
// 对线程调用Wait方法(或者求Result)不是最好的办法,因为它会阻滞主线程,并且CLR在后台会新起线程池线程来完成额外的工作
static void Main(string[] args)
{
Task t = new Task(() => { throw new InvalidOperationException("任务并行编码中产生的未知异常"); });
t.Start();
Task tEnd = t.ContinueWith((task) => { throw task.Exception; }, TaskContinuationOptions.OnlyOnFaulted);
try
{
// 异常
tEnd.Wait();
}
catch (AggregateException err)
{
foreach (var item in err.InnerExceptions)
{
Console.WriteLine("异常类型:{0}{1}来自于:{2}{3}异常内容:{4}", item.InnerException.GetType(),
Environment.NewLine, item.InnerException.Source, Environment.NewLine,
item.InnerException.Message);
}
}
Console.WriteLine("主线程马上结束");
Console.ReadKey();
}
// 异常类型:System.InvalidOperationException
// 来自于:Tip85
// 异常内容:任务并行编码中产生的未知异常
// 主线程马上结束
故事并没有到此结束。对线程调用Wait方法(或者求Result)不是最好的办法,因为它会阻滞主线程,并且CLR在后台会新起线程池线程来完成额外的工作。如果要包装异常到主线程,另外一个方法就是使用事件通知的方式:
static event EventHandler<AggregateExceptionArgs> AggregateExceptionCatched;
public class AggregateExceptionArgs : EventArgs
{
public AggregateException AggregateException { get; set; }
}
static void Main(string[] args)
{
AggregateExceptionCatched += new EventHandler<AggregateExceptionArgs>(Program_AggregateExceptionCatched);
Task t = new Task(() =>
{
try
{
throw new InvalidOperationException("任务并行编码中产生的未知异常");
}
catch (Exception err)
{
AggregateExceptionArgs errArgs = new AggregateExceptionArgs()
{AggregateException = new AggregateException(err)};
AggregateExceptionCatched(null, errArgs);
}
});
t.Start();
Console.WriteLine("主线程马上结束");
Console.ReadKey();
}
static void Program_AggregateExceptionCatched(object sender, AggregateExceptionArgs e)
{
foreach (var item in e.AggregateException.InnerExceptions)
{
Console.WriteLine("异常类型:{0}{1}来自于:{2}{3}异常内容:{4}", item.GetType(), Environment.NewLine, item.Source,
Environment.NewLine, item.Message);
}
}
在这个例子中,我们声明了一个委托AggregateExceptionCatchHandler,它接受两个参数,一个是事件的通知者;另一个是事件变量AggregateExceptionArgs.
AggregateExceptionArgs是为了包装异常而新建的一个类型。在主线程中,我们为事件AggregateExceptionCatched注册了事件处理方法Program_AggregateExceptionCatched,当任务Task捕获到异常时,代码引发事件。
这种方式完全没有阻滞主线程。如果是在Winform或WPF窗体程序中,要在事件处理方法中处理UI界面,还可以将异常信息交给窗体的线程模型去处理。所以,最终建议大家采用事件通知的模型处理Task中的异常。
注意: 任务调度器TaskScheduler提供了这样一个功能,它有一个静态事件用于处理未捕获到的异常。一般不建议这样使用,因为事件回调是在进行垃圾回收的时候才发生的。
建议86 : Parallel 中的异常处理
建议85阐述了如何处理Task中的异常。由于Task的Start方法是异步启动的,所以我们需要额外的技术来完成异常处理。Parallel 相对来说就要简单很多,因为Parallel的调用者线程会等到所有的任务全部完成后,再继续自己的工作。简单来说,它具有同步的特性,所以,用下面的这段代码就可以实现将并发异常包装到主线程中:
static void Main(string[] args)
{
try
{
var parallelExceptions = new ConcurrentQueue<Exception>();
Parallel.For(0, 1, (i) =>
{
try
{
throw new InvalidOperationException("并行任务中出现的异常");
}
catch (Exception e)
{
parallelExceptions.Enqueue(e);
}
if (parallelExceptions.Count > 0)
throw new AggregateException(parallelExceptions);
});
}
catch (AggregateException err)
{
foreach (Exception item in err.InnerExceptions)
{
Console.WriteLine("异常类型:{0}{1}来自于:{2}{3}异常内容:{4}", item.InnerException.GetType(),
Environment.NewLine, item.InnerException.Source, Environment.NewLine,
item.InnerException.Message);
}
}
Console.WriteLine("主线程马上结束");
Console.ReadKey();
}
在Parallel的异常处理中,我们使用了一个线程安全的泛型集合ConcurentQueue<T>来处理并发中有可能会遇到的集合线程安全性问题(参见建议22:确保集合的线程安全)。
建议87 : 区分WPF和WinForm的线程模型
WPF和WinForm窗体应用程序都有一个要求,那就是UI元素(如Button、TextBox等)必须由创建它的那个线程进行更新。WinForm在这方面的限制并不是很严格.
理论上, WinForm和WPF的线程模型非常接近,它们最后都是调用API (GetMessage或PeekMessage)来处理其他线程发送过来的消息,这些消息存储在系统的一个消息队列中。在WinForm和WPF中,创建主界面的线程就是主线程,也就是UI线程,UI线程负责处理该消息队列。只是两者在处理消息队列的,上层机制上稍微有一些不同,这就造成了同样的代码得到不同的结果。
本建议中的异常没有传递到主线程。在实际编码中,应当始终考虑将异常包装到主线程。
建议88 : 并行并不总是速度更快
并行所带来的后台任务及任务的管理,都会带来一定的开销,如果一项工作本来就能很快完成,或者说循环体很小,那么并行的速度也许会比非并行要慢。
DoSomething方法中的循环体为10时,同步只用了0.55 毫秒,而并行则使用了3.3毫秒才完成工作。现在,为了模拟让循环体做更多事情,将DoSomething方法中的循环体由10变为10000000。运行的结果为:
- 同步耗时: 00:00:01.3059138
- 并行耗时: 00: 00:00.6560593
当循环体需要做更多工作的时候,我们发现,同步需要1.3秒才能完成工作,而并行则仅使用0.6秒就完成了工作。
建议89 : 在并行方法体中谨慎使用锁
除了建议88所提到的场合,要谨慎使用并行的情况还包括:某些本身就需要同步运行的场合,或者需要较长时间锁定共享资源的场合。
在对整型数据进行同步操作时,可以使用静态类Interlocked的Add方法,这就极大地避免了由于进行原子操作长时间锁定某个共享资源所带来的同步性能损耗。回顾建议83中的例子。
static void Main(string[] args)
{
int[] nums = new int[] {1, 2, 3, 4};
int total = 0;
Parallel.For<int>(0, nums.Length, () => { return 1; }, (i, loopState, subtotal) =>
{
subtotal += nums[i];
return subtotal;
},
(x) => Interlocked.Add(ref total, x)
);
Console.WriteLine("total={0}", total);
Console.ReadKey();
}
理论上,针对total的加法操作,需要使用一个同步锁,否则就无法避免一次tornread (即两次mov操作所导致的字段内存地址边界对齐问题)。FCL通过提供Interlocked类型解决了这个问题。FCL用来解决简单类型的原子性操作还提供了volatile 关键字。不过这些都不是本建议所要讨论的重点。FCL现有的原子性操作为我们同步整型数据的时候,带来了性能上的提高。但是,在其他一些场合,我们却不得不考虑因为同步锁带来的损耗。
static void Main(string[] args)
{
SampleClass sample = new SampleClass();
Parallel.For(0, 10000000, (i) => { sample.SimpleAdd(); });
Console.WriteLine(sample.SomeCount);
}
class SampleClass
{
public long SomeCount { get; private set; }
public void SimpleAdd()
{
SomeCount++;
}
}
// 1269197
显然,这与我们的期待输出10000000有很大的差距。为了保证输出正确,必须为并行中的方法体加锁(假设SampleClass是外部提供的API,无权进行源码修改在其内部加锁) :
object syncObj = new object();
Parallel.For(0, 10000000, (i) =>
{
lock (syncObj)
{
sample.SimpleAdd();
}
});
经过以上:修改后,代码输出就正确了。但是,这段代码也带来了另外的问题。由于锁的存在,系统的开销也增加了,同步带来的线程上下文切换,使我们牺牲了CPU时间与空间性能。简单地说,就是这段代码还不如不用并行。在建议73中曾经提到过,锁其实就是让多线程变成单线程( 因为同时只允许有一个线程访问资源)。所以,我们需要谨慎地对待并行方法中的同步问题。如果方法体的全部内容都需要同步运行,就完全不应该使用并行。
