运行时序列化
序列化 是将对象或对象图转换成字节流的过程,反序列化是将字节流转换回对象图的过程。在对象和字节流之间转换是很有用的机制。
- 应用程序的状态(对象图)可轻松保存到磁盘文件或数据库中,并在应用程序下次运行时恢复。ASP.NET就是利用序列化和反序列来保存和还原会话状态。
- 一组对象可轻松复制到系统的剪贴板,再粘贴回同一个或另一个应用程序。事实上,windows窗体和Windows Presentation Foundation(WPF)就利用了这个功能。
- 一组对象可克隆并放到一边作为“备份”;与此同时,用户操纵一组“主”对象。
- 一组对象可轻松地通过网络发送给另一台机器上运行的进程。Microsoft .Net Framework的Remoting(远程处理) 架构会对按值封送(marshaled by value)的对象进行序列化和反序列化。这个技术还可跨AppDomain边界发送对象。
除了上述应用,一旦将对象序列化成内存中的字节流,就可方便地以一些更有用的方式处理数据,比如进行加密和压缩。
由于序列化如此有用,所以许多程序员耗费了大量时间写代码执行这些操作。历史上,这种代码很难编写,相等繁琐,还容易出错。开发人员需要克服的难题包括通信协议、客户端/服务器数据类型不匹配(比如低位优先/高位优先问题)、错误处理、一个对象引用了其他对象、in和out参数以及由结构构成的数组。
让人高兴的是,.Net Framework内建了出色的序列化和反序列化支持。上述所有难题都迎刃而解,而且.Net Framework是在后台悄悄帮你解决的。开发者现在只需负责序列化之前和反序列化之后的对象处理,中间过程由.Net Framework负责。
本章解释了.Net Framework如何公开它的序列化和序列化服务。对于几乎所有数据类型,这些服务的默认行为已经足够。也就是说,几乎不需要做任何工作就可以使自己的类型“可序列化”。但对于少量类型,序列化服务的默认行为是不够的。幸好,序列化服务的扩展性极佳,本章将解释如何利用这些扩展性机制,在序列化或反序列化对象时采取一些相当强大的操作。
注意:本章重点在于CLR的运行时序列化技术。这种技术对CLR数据类型有很深刻的理解,能将对象的所有公共、受保护、内部甚至私有字段序列化到压缩的二进制流中,从而获得很好的性能。 要把CLR数据类型序列化成XML流, 参见System.Runtime.Serialization.NetDataContractSerializer类. .Net Framework还提供了其他序列化技术, 它们主要是为了CLR数据类型和非CLR数据类型之间的互操作而设计的. 这些技术用的是System.Xml.Serialization.XmlSerializer类和System.Runtime.Serialization.DataContractSerializer类.
序列化/反序列化快速入门
static void Main(string[] args)
{
//创建对象图以便把它们序列化到流中
var objectGraph = new List<string> {"Jeff", "Kristin", "Aidan"};
Stream stream = SerializeToMemory(objectGraph);
//为了演示,将一切都重置
stream.Position = 0;
objectGraph = null;
//反序列化对象,证明它能工作
objectGraph = (List<string>) DeserializeFromMemory(stream);
foreach (var s in objectGraph)
{
Console.WriteLine(s);
}
}
private static MemoryStream SerializeToMemory(object objectGraph)
{
//构造流来容纳序列化对象
MemoryStream stream = new MemoryStream();
//构造序列化格式化器来执行所有真正的工作
BinaryFormatter formatter = new BinaryFormatter();
//告诉格式化器将对象序列化到流中
formatter.Serialize(stream,objectGraph);
//将序列化好的对象流返回给调用者
return stream;
}
private static object DeserializeFromMemory(Stream stream)
{
//构造序列化格式器来做所有真正的工作
BinaryFormatter formatter = new BinaryFormatter();
//告诉格式化器从流中反序列化对象
return formatter.Deserialize(stream);
}
一切视乎都很简单!SerializeToMemory方法构造一个System.Io.MemoryStream对象。这个对象表明要将序列化好的字节块放在哪儿。然后,方法构造一个BinaryFormatter对象(在System.Runtime.Serialization.Formatters.Binary命名空间中定义)。格式化器是实现了System.Runtime.Serialization.IFormatter接口的类型,它知道如何序列化和反序列化对象图。
序列化对象图只需调用格式化器的Serialize方法,并向它传递两样东西:对流对象的引用,以及对想要序列化的对象图的引用。流对象表示了序列化好的字节应该放到哪里,它可以是从System.IO.Stream抽象基类派生的任何类型的对象。 也就是说对象图可序列化成一个MemoryStream,FileStream或者NetworkStream等.
格式化器参考对每个对象的类型进行描述的元数据,从而了解如何序列化完整的对象图。序列化时,Serialize方法利用反射来查看每个对象的类型中都有哪些实例字段。在这些字段中,任何一个引用了其他对象,格式化器的Serialize方法就知道哪些对象也要进行序列化。
格式化器的算法非常智能。他们知道如何确保对象图中的每个对象都只序列化一次。换言之,如果对象图中的两个对象互相引用,格式化器会检测到这一点,每个对象都只序列化一次,避免发生死循环。
在内部,格式化器的Deserialize方法检查流的内容,构造流中所有对象的实例,并初始化所有这些对象中的字段,使它们具有与当初序列化时相同的值。通常要将Deserialize方法返回的对象引用转型为应用程序期待的类型。
利用序列化创建对象的深拷贝:
private static object DeepClone(object original)
{
//构造临时内存流
using (MemoryStream stream = new MemoryStream())
{
//构造序列化格式器来做所有真正的工作
BinaryFormatter formatter = new BinaryFormatter();
// 之后讲解 "流上下文"
formatter.Context = new StreamingContext(StreamingContextStates.Clone);
//将对象图序列化到内存流中
formatter.Serialize(stream, original);
//反序列化前,定位到内存流的起始位置
stream.Position = 0;
//将对象图反序列化成一组新对象,向调用者返回对象图(深拷贝)的根
return formatter.Deserialize(stream);
}
}
有几点需要注意。首先,是由你来保证代码为序列化和反序列化使用相同的格式化器。其次,可以将多个对象图序列化到一个流中,这是很有用的一个操作。例如,假定有以下两个类定义:
[Serializable]
internal sealed class Customer{}
[Serializable]
internal sealed class Oreder{}
然后,在应用程序的主要类中定义了以下静态字段:
private static List<Customer> s_customers = new List<Customer>();
private static List<Oreder> s_pendingOrders = new List<Oreder>();
private static List<Oreder> s_processedOrders= new List<Oreder>();
现在,可利用如下所示方法将应用程序的状态序列化到单个流中:
private static void SaveApplicationState(Stream stream)
{
//构造序列化格式器来做所有真正的工作
BinaryFormatter formatter = new BinaryFormatter();
//序列化我们的应用程序的完整状态
formatter.Serialize(stream,s_customers);
formatter.Serialize(stream,s_pendingOrders);
formatter.Serialize(stream,s_processedOrders);
}
最后一个注意事项与程序集有关。序列化对象时,类型的全名和类型定义程序集的全名会被写入流。BinaryFormatter默认输出程序集的完整表示,其中包括程序集的文件名(无扩展名)、版本号、语言文化以及公钥信息。反序列化对象是,格式化器首先获取程序集标识信息,并通过调用System.Reflection.Assembly的Load方法确保程序集已加载到正在执行的Appdomain中。
程序集加载好之后,格式化器在程序集中查找与要反序列化的对象匹配的类型
- 找不到匹配类型就抛出异常,不再对更多的对象进行反序列化。
- 找到匹配的类型,就创建类型的实例,并用流中包含的值对其字段字段进行初始化。
- 如果类型中的字段与流中读取的字段名不完全匹配,就抛出
SerializationException异常,不再对更多的对象进行反序列化。
关于Assembly.LoadFrom加载程序集的相关问题

反序列化会调用Assembly.Load而非LoadFrom, 一般情况下无法定位程序集, 造成SerializationException异常.
如果这样做了, 建议在调用格式化器的Deserialize方法之前, 实现一个方法, 它的签名匹配System.ResolueEventHandler委托. 并向AppDomain的AssemblyResolve事件注册这个方法. Deserialize方法结束后,马上向事件注销这个方法. 现在每个格式化器加载一个程序集失败,CLR都会自动调用你的ResolueEventHandler方法, 加载失败的程序集的标识会传给这个方法, 方法可以从程序集的标识知道去哪里寻找文件. 然后方法可调用Assembly.LoadFrom加载程序集, 最后返回对结果程序集的引用.
使类型可序列化
设计类型时,设计人员必须郑重地决定是否允许类型的实例序列化。类型默认是不可序列化的。开发者必须向类型应用定制特性System.SerializableAttribute。任何对象不可序列化,格式化器的Serialize方法都会抛出异常。
注意: 序列化对象图时, 也许有的对象的类型能序列化,有的不能. 考虑到性能, 在序列化之前, 格式化器不会验证对象图中的所有对象都能序列化. 所以序列化对象图时, 在抛出SerializationException异常之前, 完全有可能已经有一部分对象序列化到流中, 如果发生这种情况, 流中就会包含已损坏的数据.
序列化对象图时, 如果你认为有一些对象不可序列化, 那么写的代码就应该能得体地从这种情况中恢复. 一个方案是,先将对象序列化到MemoryStream中, 然后如果所有对象都成功序列化, 才将MemoryStream中的字节复制到你正在希望的目标流(文件或网络流)中.
SerializableAttribute定制特性只能应用于引用类型(class), 值类型(struct),枚举类型(enum)和委托类型(delegate). 注意, 枚举和委托类型总是可序列化的.所以不必显式应用此特性. 除此之外,此特性不会被派生类型继承.
如果基类型没有应用SerializableAttribute定制特性, 那么很难想象如何从它的派生出可序列化的类型. 这样设计的原因是如果基类型不允许它的实例序列化, 它的字段就不能序列化. 因为基对象实际就是派生对象的一部分. 这也是基对象Object已经应用了SerializableAttribute特性的原因.
一般建议将你定义的大多数类型都设置成可序列化. 毕竟, 这样能为类型的用户提供很大的灵活性. 但必须注意的是, 序列化会读取对象的所有字段. 不管这些字段声明为public, protected,internal,private. 如果类型的实例要包含敏感或安全数据(比如密码), 或者数据在转移之后便没有含义或者没有值, 就不应该使类型变得可序列化.
控制序列化和反序列化
用SerializableAttribute定制特性应用于类型, 但类型可能定义了一些不应序列化的实例字段. 一般有两个原因造成我们不想序列化部分实例字段:
- 字段含有反序列化后变得无效的信息.
- 例如, 对象包含Windows内核对象(如文件、进程、线程、互斥体、事件、信号量等)的句柄,那么在反序列化到另一个进程或另一台机器之后,就会失去意义。因为Windows内核对象是跟进程相关的值。
- 字段含有很容易计算的信息.
- 这时要选出哪些无须序列化的字段, 减少需要传输的数据, 增强应用程序的性能.
以下代码使用System.NonSerializedAttribute定制特性指出类型中不应序列化的字段.注意,该特性只能应用于类型中的字段,而且会被派生类型继承。
[Serializable]
public class Circle
{
private Double m_radius;
[NonSerialized]
private Double m_area;
public Circle(Double radius)
{
m_radius = radius;
m_area = Math.PI * m_radius * m_radius;
}
}
上述代码中, Circle对象可以序列化, 但格式化器只会序列化对象的m_radius字段的值. m_area的值不会被序列化, 因为字段应用了[NonSerialized]特性. 并且会被派生类型继承.
假如构造一个Circle对象: Circle c = new Circle(10);, 在内部, m_area值会设置成一个月为314.159的值. 这个对象序列化时, 只有m_radius字段的值(10)才会写入流. 但当流反序列化Circle对象时, 就会遇到一个问题, Circle对象的m_radius值会被设为10, 但它的m_area字段会被初始化成0, 而不是314.159 !
以下代码演示如何修正上述问题:
[Serializable]
public class Circle
{
private Double m_radius;
[NonSerialized]
private Double m_area;
public Circle(Double radius)
{
m_radius = radius;
m_area = Math.PI * m_radius * m_radius;
}
[OnDeserialized]
private void OnDeserialized(StreamContext context)
{
m_area = Math.PI * m_radius * m_radius;
}
}
要在对象反序列化时调用一个方法, System.Runtime.Serialization.OnDeserialized 定制特性时首选方案, 而不是上类型实现 System.Runtime.Serialization.IDeserializationCallback接口的OnDeserialized方法
应用了此特性[OnDeserialized]的方法, 每次反序列化类型的实例, 格式化器都会检查类型中是否定义了应用该特性的方法, 如果是,就调用该方法, 从而确保对象的完全反序列化.
OnSerializingAttributeOnSerializedAttributeOnDeserializingAttributeOnDeserializedAttribute
可以将它们应用于类型汇总定义的方法, 对序列化和反序列化过程进行更多的控制.
[Serializable]
public class MyType
{
private int x, y;
[NonSerialized] private int sum;
public MyType(int x,int y)
{
this.x = x;
this.y = y;
sum = x + y;
}
[OnDeserializing]
private void OnDeserializing(StreamingContext context)
{
// 在类型的新版本中,(反序列化开始时)为字段设置默认值
}
[OnDeserialized]
private void OnDeserialized(StreamingContext context)
{
// 反序列化结束后, 根据字段值初始化瞬时状态比如sum值
sum = x + y;
}
[OnSerializing]
private void OnSerializing(StreamingContext context)
{
// 在序列化前, 修改任何需要修改的状态
}
[OnSerialized]
private void OnSerialized(StreamingContext context)
{
// 在序列化后, 恢复任何需要恢复的状态
}
}
使用这4个属性中的任何一个时, 你定义的方法必须获取一个StreamingContext参数”流上下文”, 并返回void. 方法名可以是任意名称, 且方法声明为private,以免被普通的代码调用; 格式化器运行时有充足的安全权限. 所以能调用私有方法.
序列化一组对象时,
- 格式化器首先调用对象的标记了
[OnSerializing]的所有方法. - 接着序列化对象的所有字段
- 最后完调用对象的标记了
[OnSerialized]的所有方法
反序列化一组对象时,
- 首先, 格式化器调用对象的标记了
[OnDeserializing]的所有方法. - 然后, 它反序列化对象的所有字段.
- 最后, 调用对象的标记了
[OnDeserialized]的所有方法.
反序列化期间, 格式化器处理带有[OnDeserialized]特性的方法时, 会将这个对象的引用添加到一个内部列表中. 所有对象都反序列化之后, 格式化器反向遍历列表. 之所以要以相反的顺序调用这些方法, 因为这样才能使内层对象先于外层对象完成反序列化.
例如, Hashtable或Dictonary内部用了一个哈希表维护它的数据项列表. 这个集合中的对象类型有标记了[OnDeserialized]特性的方法(用于反序列化之后的操作). 即使集合对象先反序列化(先于它包含的数据项). 它的[OnDeserialized]方法也会最后调用(在调用完它的数据项的所有[OnDeserialized]方法之后). 这样一来, 所有数据项在反序列化后它们的所有字段都能得到正确的初始化, 以便计算出一个好的哈希码值. 利用哈希码将数据放到内部哈希桶中.
如果序列化类型的实例, 在类型中添加新字段, 然后视图反序列化不包含新字段的对象, 格式化器就会抛出SerializationException异常, 并显示一条消息告诉你流中要反序列化的数据包含错误的成员数目. 这时可以利用System.Runtime.Serialization.OptionalFieldAttribute特性. 类型中新增的每个字段都要应用[OptionalField]特性(可选字段), 这样格式化器就不会因为流中的数据不包含这个字段而抛出SerializationException异常.
格式化器如何序列化类型实例
本节将深入讨论格式化器如何序列化对象的字段。为了简化格式化器的操作,FCL在System.Runtime.Serialization命名空间提供了一个FormatterServices类型。该类型只包含静态方法,而且该类型不能实例化。
以下步骤描述了格式化器如何自动序列化类型应用Serializable特性的对象。
格式化器调用
FormatterService的GetSerializableMembers方法.public static MemberInfo[] GetSerializableMembers(Type type, StreamingContext context);这个方法利用反射获取类型的
public和private实例字段(标记了NonSerializedAttribute特性的字段除外). 方法返回由MemberInfo对象构成的数组, 其中每个元素都对应一个可序列化的实例字段.对象被序列化,
System.Reflection.MemberInfo对象数组传给FormatterServices的静态方法GetObjectData
public static object[] GetObjectData(object obj, MemberInfo[] members);
这个方法返回一个Object数组, 每个元素都表示了被序列化的那个对象中的一个字段的值. 这个Object数组和MemberInfo数组是并行的. 换言之, Object数组中的元素0是MemberInfo数组中的元素0所标识的那个成员的值.
- 格式化器将程序集标识和类型的完整名称写入流中。
- 格式化器然后遍历两个数组中的元素,将每个成员的名称和值写入流中。
以下步骤描述了格式化器如何自动反序列化类型应用Serializable特性的对象。
- 格式化器从流中读取程序集标识和完整类型名称. 如果程序集当前没有加载到AppDomain中, 就加载它,如果加载失败就抛出
SerializationException异常,程序集已加载,格式化器将程序集标识信息和类型全名传给FormatterServices的静态方法GetTypeFromAssembly;
public static Type GetTypeFromAssembly(Assembly assem, String name);
这个方法返回一个System.Type对象, 它代表要反序列化的那个对象的类型.
- 格式化器调用
FormatterServices的静态方法GetUninitializedObject:
public static Object GetUninitializedObject(Type type);
这个方法为一个新对象分配内存, 但不为对象调用构造器. 然而, 对象的所有字节都被初始化成null或0.
格式化器现在构造并初始化一个
MemberInfo数组, 具体做法和前面一样, 都是调用FormatterServices的GetSerializableMembers方法, 这个方法返回序列化好,现在需要反序列化的一组字段.格式化器根据流中包含的数据创建并初始化一个Object数组.
- 将新分配对象, MemberInfo数组(包含字段类型)以及并行Object数组(包含字段值)的引用传给
FormatterServices的静态方法PopulateObjectMembers:
public static Object PopulateObjectMembers(Object obj, MemberInfo[] members, Object[] data);
这个方法遍历数组, 将每个字段初始化成对应的值. 到此为止, 对象就算是被彻底反序列化了.
控制序列化/反序列化的数据
本章前面讨论过,控制序列化和反序列过程的最佳方式就是使用OnSerializing等特性。然后,一些极少的情况下,这些特性不能提供你想要的全部控制。此外,格式化器(Formatter)内部使用的是反射,而反射的速度是比较慢的,这会增大序列化和反序列化对象所花的时间。
为了对序列化、反序列化的数据进行完全控制,并避免使用反射,你的类型可实现System.Runtime.Serialization. ISerializable接口,定义如下:
public interface ISerializable
{
void GetObjectData(SerializationInfo info, StreamingContext context);
}
这个接口只有一个方法,即GetObjectData。但实现这个接口的大多数类型还实现了一个特殊的构造器。
重要提示:ISerializable接口最大的问题在于,一旦类型实现了它,所有派生类型也必须实现它,而且派生类型必须保证调用基类的GetObjectData方法和特殊构造器。此外,一旦类型实现了该接口,便永远不能删除它,否则会时区与派生类型的兼容性。所以,密封类实现ISerializable接口是最让人放心的。
ISerializable接口和特殊构造器旨在由格式化器使用, 但其他代码可能调用GetObjectData来返回敏感数据. 另外其他代码可能构造对象, 并传入损坏的数据. 因此, 建议向GetObjectData方法和特殊构造器应用以下特性:
// .net framework 4.8 中 此 API 现已过时。
[SecurityPermissionAttribute(SecurityAction.Demand, SerializionFormatter = true)]
格式化器 序列化对象图时会检查每个对象。如果发现一个对象的类型实现了ISerializable接口,就会忽略所有定制特性,改为构造新的System.Runtime.Serialization.SerializationInfo对象。该对象包含了要为对象序列化的值的集合。
构造SerializationInfo对象时,格式化器要传递两个参数:Type和System.Runtime.Serialization.IFormatterConverter。Type参数标识要序列化的对象。
- 类型的全名
SerializationInfo.FullTypeName - 程序集的标识
SerializationInfo.AssemblyName - 构造器获取类型的定义程序集: 内部查询
Type的Module属性, 再查询Module的Assembly属性, 再查询Assembly的FullName属性.

构造好并初始化好SerializationInfo对象后,格式化器调用类型的GetObjectData方法,向它传递对SerializationInfo对象的引用。GetObjectData调用SerializationInfo类型提供的AddValue方法的众多重载版本之一来指定要序列化的信息。针对要添加的每个数据,都要调用一次AddValue。
以下代码展示了Dictionary<TKey,TValue>类型如何实现ISerializable和IDeserializationCallback接口来控制其对象的序列化和反序列化。
[Serializable]
public class Dictionary<TKey, TValue> : ISerializable, IDeserializationCallback
{
// 其他一些私有字段未列出
private SerializationInfo m_siInfo;//只用于反序列化
//用于控制反序列化的特殊构造器(这是ISerializable需要的)
[SecurityPermission(SecurityAction.Demand, SerializationFormatter = true)]
protected Dictionary(SerializationInfo info, StreamingContext context)
{
//反序列化期间,为OnDeserialization保存SerializationInfo
m_siInfo = info;
}
//用于控制序列化的方法
[SecurityCritical]
public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
{
info.AddValue("Version",m_version);
//......
}
//所有key/value对象都反序列化好之后调用的方法
public virtual void IDeserializationCallback.OnDeserialization(object sender)
{
if (m_siInfo==null)
{
return;//从不设置,直接返回
}
// ....
}
}
每个Addvalue方法都获取一个String名称和一些数据。数据一般是简单的值类型。然后,还可以在调用AddValue时向它传递对一个object的引用。GetObjectData添加好所有必要的序列化信息之后,会返回至格式化器。

现在,格式化器获取已添加到SerializationInfo对象的所有值, 并把它们都序列化到流中. 我们还向GetObjectData方法传递了另一个参数 StreamingContext对象的引用, 大多数类型的GetObjectData都会完全忽略这个参数.
知道了如何设置序列化所需的全部信息之后,再来看反序列化。格式化器从流中提取一个对象时,会为新对象分配内存(FormatterService的静态方法GetUninitializedObject)。最初,这个对象的所有字段都设为0或者null。然后,格式化器检查类型是否实现了ISerializable接口。如果存在这个接口,格式化器就尝试调用一个特殊构造器,他的参数和GetObjectData方法完全一致。
如果是密封类,强烈建议声明特殊构造器为private防止任何代码不慎调用到它. 而不是密封类, 则声明为protected,确保只有派生类才能调用. 但是无论怎么声明,格式化器都能调用它.
构造器获取了SerializationInfo对象引用, 其中包含了序列化时添加的所有值. 特殊构造器可调用GetInt,GetString等Get方法, 向它传递与序列化一个值所用的名称对应的字符串. 获取的值再去初始化字段.
反序列化对象的字段时,应调用和对象序列化时传给AddValue方法的值的类型匹配的get方法。换言之,如果GetObjectData方法调用AddValue时传递的是一个int值,那么在反序列化对象时,应该为同一个值调用GetInt32方法。如果值在流中的类型和你试图获取get的类型不符,格式化器会尝试用一个IFormatterConverter对象将流中的值类型转型成你指定的类型。
FormatterConverter会调用System.Convert类的各种静态方法在不同的核心类型之间对值进行转换. (比如Int64转成一个Int32), 然而,为了在其他任意类型之间转换一个值, FormatterConverter要调用Convert类的ChangeType方法将序列化好的类型转型为一个IConvertible接口, 再调用恰当的接口方法.
所以要允许一个可序列化类型的对象反序列化成一个不同的类型, 可考虑让自己的类型实现IConvertible接口. 注意, 只有在反序列化对象时调用一个Get方法,发现它的类型和流中的类型不符时,才会使用FormatterConverter对象.
特殊构造器也可以不调用上面列出的各个Get方法, 而是调用GetEnumerator. 该方法返回一个SerializationInfo.Enumerator对象, 可用该对象遍历SerializationInfo对象中包含的所有值. 枚举的每个值都是一个SerializationEntry对象.
当然, 完全可以定义自己的类型, 让它从实现了ISerializable的GetObjectData方法和特殊构造器的类型派生. 如果你的类型也实现了ISerializable, 那么在你实现的GetObjectData方法和特殊构造器中,必须调用基类中的同名方法. 确保对象能正确序列化和反序列化. 这一点很重要.

要实现ISerializable但基类型没有实现怎么办?
前面讲过,ISerializable接口的功能非常强大,允许类型完全控制如何对类型的实例进行序列化和反序列化。但这个能力是有代价的:现在,该类型还要负责它的基类型的所有字段的序列化。如果基类型也实现了ISerializable接口,那么对基类型的字段进行序列化时很容易。调用基类型的GetObjectData即可。
但是如果基类型没有实现ISerializable接口,在这种情况下,派生类必须手动序列化基类的字段。具体的做法是获取它们的值,并把这些值添加到SerializationInfo集合中。然后,在你的特殊构造器中,还必须从集合中取出值,并以某种方式设置基类的字段。如果是public或者protected的,那么一切很容易实现, 如果是private字段,就不可能实现.
以下代码演示了如何正确实现ISerializable接口的GetObjectData方法和它的隐含的构造器, 使基类的字段能被序列化:
[Serializable]
internal class Base
{
protected string m_name = "Jeff";
public Base(){}
}
[Serializable]
internal class Derived:Base,ISerializable
{
private DateTime m_date=DateTime.Now;
public Derived(){}
// 如果这个构造器不存在, 便会引发一个SerializationException异常
// 如果这个类不是密封类, 这个构造器就应该是protected的
[SecurityPermission(SecurityAction.Demand,SerializationFormatter = true)]
private Derived(SerializationInfo info, StreamingContext context)
{
//为我们的类和基类获取可序列化的成员集合
Type baseType = this.GetType().BaseType;
MemberInfo[] mi = FormatterServices.GetSerializableMembers(baseType, context);
//从info对象反序列化基类的字段
for (int i = 0; i < mi.Length; i++)
{
//获取字段,并把它设为反序列化好的值
FieldInfo fi = (FieldInfo) mi[i];
fi.SetValue(this,info.GetValue(baseType.FullName+"+"+fi.Name,fi.FieldType));
}
//反序列化为这个类序列化的值
m_date = info.GetDateTime("Date");
}
[SecurityPermission(SecurityAction.Demand,SerializationFormatter =true)]
public virtual void GetObjectData(SerializationInfo info, StreamingContext context)
{
//为这个类序列化希望的值
info.AddValue("Date",m_date);
//获取我们的类和基类的可序列化的成员
Type baseType = this.GetType().BaseType;
MemberInfo[] mi = FormatterServices.GetSerializableMembers(baseType, context);
//将基类的字段序列化到info对象中
for (int i = 0; i < mi.Length; i++)
{
//为字段名附加基类型全名作为前缀
info.AddValue(baseType.FullName+"+"+mi[i].Name, ((FieldInfo)mi[i]).GetValue(this));
}
}
public override string ToString()
{
return string.Format("Name={0},Date={1}", m_name, m_date);
}
}
上述代码有一个名为Base的基类,它只用SerializableAttribute定制特性进行标识, 从它派生的Derived类,除了应用了此特性还实现了ISerializable接口. 两个类都定义了m_name的String字段, 调用SerializationInfo的AddValue不能添加多个同名值. 解决这个问题的方案是在字段名前附加类名作为前缀. 从而对每个字段进行标识. 例如, 当GetObjectData方法调用AddValue来序列化Base的m_name字段时, 写入的值名称是”Base+m_name”.
流上下文
前面讲过,一组序列化好的对象可以有许多目的地:同一个进程、同一台机器上的不同进程、不同机器上的不同进程等。在一些比较少见的情况下,一个对象可能想知道它要在什么地方反序列化,从而以不同的方式生产它的状态。例如,如果对象中包装了windows信号量对象,如果它知道要反序列化到同一个进程,就可决定对它的内核句柄进行序列化,这是因为内核句柄在一个进程中有效。但如果要反序列化到同一台计算机的不同进程中,就可决定对信号量的字符串名称名称进行序列化。最后,如果要反序列化到不同计算机上的进程,就可决定抛出异常,因为信号量只在一台机器内有效。
本章提到的大量方法都接受一个StreamingContext(流上下文)。StreamingContext结构是一个非常简单的值类型,它只提供了两个公共只读属性,如下:

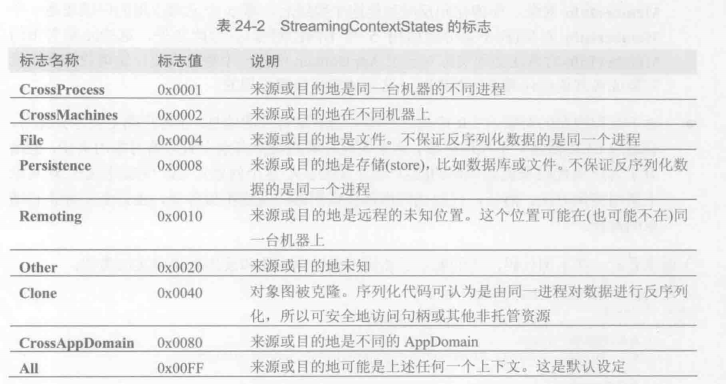
知道如何获取这些信息后,接着讨论如何设置。IFormatter接口定义了StreamingContext类型的可读写属性Context。构造格式化器时,格式化器会初始化它的Context属性,将StreamingContextStates设为All,将对额外状态对象的引用设为null。
格式化器构造好之后,就可以使用任何StreamingContextStates位标志来构造一个StreamingContext结构,并可选择传递一个对象(包含你需要的任何额外的上下文信息)引用。现在,在调用格式化器的Serialize或Deserialize方法之前,你只需要将格式化器的context属性设为这个新的StreamingContext对象。
类型序列化为不同类型以及对象反序列化为不同对象
.Net Framework的序列化架构是相当全面的,本节要讨论如何设计类型将自己序列化或反序列化成不同的类型或对象。下面列举了一些有趣的例子。
有的类型(比如
System.DBNull和System.Reflection.Missing)设计为每个Appdomain一个实例。经常将这些类型称为单实例(Singleton)类型。给定一个DBNull对象引用,序列化和反序列化它不应造成在appdomain中新建一个DBNull对象,反序列化后,返回的引用应指向appdomain中现有的DBNull对象。对某些类型(比如
System.Type和System.Reflection.Assembly,以及其他反射类型,例如MemberInfo),每个类型、程序集或成员等都只能有一个实例。例如,假定一个数组中的每个元素都引用一个MemberInfo对象,其中5个元素引用的都是一个MemberInfo对象。序列化和反序列化这个数组后,那5个元素引用的应该还是一个MemberInfo对象。除此之外,这些元素引用的MemberInfo对象还必须实际对应于Appdomain中的一个特定成员。轮询数据库连接对象或者其他任何类型的对象时,这个功能也是很好用的。对于远程控制的对象,CLR序列化与服务器对象有关的信息。在客户端上反序列化时,会造成CLR创建一个代理对象。这个代理对象的类型有别于服务器对象的类型,但这对于客户端代码来说是透明的(客户端不需要关心这个问题)。客户端直接在代理对象上调用实例方法。然后,代理代码内部会调用远程发送给服务器,由后者实际执行请求操作。
如何正确的序列化和反序列化单实例类型:
[Serializable]
public sealed class Singleton : ISerializable
{
//这是该类型的一个实例
private static readonly Singleton s_theOneObject = new Singleton();
//这些是实例字段
public string Name = "Jeff";
public DateTime Date=DateTime.Now;
//私有构造器,允许这个类型构造单实例
private Singleton(){}
//该方法返回对单实例的引用
public static Singleton GetSingleton()
{
return s_theOneObject;
}
// 序列化一个singleton时调用的方法
// 我建议在这里使用一个显式接口方法实现(eimi)
[SecurityPermission(SecurityAction.Demand,SerializationFormatter = true)]
void ISerializable.GetObjectData(SerializationInfo info, StreamingContext context)
{
info.SetType(typeof(SingletonSerializationHelper));
// 不需要设置其他值
}
[Serializable]
private sealed class SingletonSerializationHelper:IObjectReference
{
//这个方法在对象(它没有字段)反序列化之后调用
public object GetRealObject(StreamingContext context)
{
return Singleton.GetSingleton();
}
}
// 特殊构造器是不必要的,因为它永远不会调用
}
Singleton类所代表的类型规定每个AppDomain只能存在它的一个实例. 以下是测试序列化和反序列化代码:
static void Main(string[] args)
{
// 创建数组,其中多个元素引用一个singleton对象
Singleton[] a1 = { Singleton.GetSingleton(), Singleton.GetSingleton() };
Console.WriteLine("两个元素都指向同一个对象吗?"+(al[0]==al[1])); // True
using (var stream = new MemoryStream())
{
BinaryFormatter formatter=new BinaryFormatter();
//先序列化再反序列化数组元素
formatter.Serialize(stream, a1);
stream.Position = 0;
Singleton[] a2 = (Singleton[]) formatter.Deserialize(stream);
//证明它的工作和预期一样
// 证明a2数组的两个元素引用的同一个对象
Console.WriteLine("两个都指向同一个对象吗?"+(a2[0]==a2[1]));//true
// 两个数组中的元素引用是同一个对象
Console.WriteLine("所有的元素都指向同一个对象吗?"+(a1[0]==a2[0]));//true
}
}
现在,我们通过分析代码来理解所发生的事情。Singleton类型加载到Appdomain中时,CLR调用它的静态构造器来构造一个Singleton对象,并将对它的引用保存到静态字段s_theOneObject中。Singleton类没有提供任何公共构造器,这防止了其他任何代码构造该类的其他实例。
formatter.Serialize时, 格式器检测到Singleton类型实现了ISerializable接口. 并调用GetObjectData方法, 这个方法调用SetType,向它传递SingletonSerializationHelper对象, 由于没有调用AddValue, 所以没有额外的字段信息写入流. 格式化器自动检测出两个数组元素都引用一个对象. 所以格式化器只序列化一个对象.
序列化数组之后,调用格式化器的Deserialize方法。对流进行反序列化时,格式化器尝试反序列化一个SingletonSerializationHelper对象,这是格式化器之前被“欺骗”所序列化的东西(事实上着正是为什么Singleton类不提供特殊构造器的原因, 实现了ISerializable接口的通常都需要提供这个特殊构造器)。构造好SingletonSerializationHelper对象后,格式化器发现这个类型实现了System.Runtime.Serialization.IObjectReference接口。
public interface IObjectReference
{
Object GetRealObject(StreamingContext context);
}
如果类型实现了这个接口,格式化器会调用GetRealObject方法。这个方法返回在对象反序列化好之后你真正想引用的对象。在我的例子中,SingletonSerializationHelper类型让GetRealObject返回对Appdomain中已经存在的Singleton对象的一个引用。所以,当格式化器的Deserialize方法返回时,a2数组包含两个元素,两者都引用Appdomain的Singleton对象。用于帮助进行反序列化的SingletonSerializationHelper对象立即变得“不可达”了,将来会被垃圾回收。
序列化代理
格式化器还允许不是“类型实现的一部分”的代码重写该类型“序列化和反序列化其对象”的方式。应用程序代码之所以要重写(覆盖)类型的行为,主要是出于两方面的考虑。
- 允许开发人员序列化最初没有设计要序列化的类型。
- 允许开发人员提供一种方式将类型的一个版本映射到类型的一个不同的版本。
简单地说,为了使这个机制工作起来,首先要定义一个“代理类型”(surrogate type),它接管对现有类型进行序列化和反序列化的行动。然后,向格式化器登记该代理类型的实例,告诉格式化器代理类型要作用于现有的哪个类型。一旦格式化器要对现有类型的实例进行序列化和反序列化,就调用由你的代理对象定义的方法。下面例子演示这一切如何工作:
序列化代理类型必须实现ISerializationSurrogate接口,如下定义
public interface ISerializationSurrogate
{
void GetObjectData(Object obj, SerializationInfo info, StreamingContext context);
object SetObjectData(object obj, SerializationInfo info, StreamingContext context, ISurrogateSelector selector);
}
假定程序含有一些DateTime对象, 其中包含用户计算机的本地值. 如果想把DateTime对象序列化到流中, 同时希望值用国际标准时间序列化, 如何操作呢? 这样一来就可以将数据通过网络流发送给世界上其他地方的另一台机器, 使DateTime值保持正确. 它能控制DateTime对象的序列化和反序列化方式.
public class UniversalToLocalTimeSerializationSurrogate:ISerializationSurrogate
{
public void GetObjectData(object obj,SerializationInfo info,StreamingContext context)
{
//将datetime从本地时间转换成UTC
info.AddValue("Date",((DateTime)obj).ToUniversalTime().ToString("u"));
}
public object SetObjectData(object obj,SerializationInfo info,StreamingContext context,ISurrogateSelector selector)
{
//将datetime从UTC转换成本地时间
return DateTime.ParseExact(info.GetString("Date"), "u", null).ToLocalTime();
}
}
GetObjectData方法在这里的工作方式与ISerializable接口的GetObjectData方法差不多, 唯一区别在于,要多获取一个额外的参数—-对要序列化的”真实”对象的引用. 上述方法中,这个对象是DateTime. 值从本地时间转换为世界时. 并将一个字符串(使用通用完整日期/事件模式来格式化)添加到SerializationInfo集合.
SetObjectData方法用于反序列化一个DateTime对象, 调用这个方法时要向它传递一个SerializationInfo对象的引用,SetObjectData从这个集合中获取字符串形式的日期, 把它解析成通用完整日期/事件模式的字符串, 然后将结果DateTime对象从世界时转换成计算机的本地时间.
传给SetObjectData第一个参数的object有点奇怪。在调用SetObjectData之前,格式化器分配(调用FormatterService的静态方法GetUninitializedObject)要代理的那个类型的实例。实例的字段全是0/null,而且没有在对象上调用构造器。SetObjectData内部的代码为了初始化这个实例的字段,可以使用传入的SerializationInfo中的值,并让SetObjectData返回null。另外,SetObjectData可以创建一个完全不同的对象,甚至创建不同类型的对象,并返回对新对象的引用。这种情况下,格式化器会忽略对传给SetObjectData对象的任何更改。
在例子中, UniversalToLocalTimeSerializationSurrogate类扮演了DateTime类型的代理的角色, DateTime是值类型, 所以obj参数引用一个DateTime的已装箱实例. 大多数值类型中的字段都无法更改, 所以我的SetObjectData方法会忽略obj参数, 并返回一个新的DateTime对象, 其中已装好了期望的值.
序列化/反序列化一个DateTime对象时,格式化器怎么知道要用这个ISerializationSurrogate类型呢?一下代码进行测试:
static void Main(string[] args)
{
using (var stream=new MemoryStream())
{
//1 构造所需的格式化器
IFormatter formatter = new BinaryFormatter();
//2 构造一个SurrogateSelector代理选择器对象
SurrogateSelector ss = new SurrogateSelector();
//3 告诉代理选择器为datetime对象使用我们的代理
ss.AddSurrogate(typeof(DateTime),formatter.Context,new UniversalToLocalTimeSerializationSurrogate());
//4 告诉格式化器使用代理选择器
formatter.SurrogateSelector = ss;
//创建一个datetime来代表机器上的本地时间,并序列化它
DateTime localTimeBeforeSerialize = DateTime.Now;
formatter.Serialize(stream,localTimeBeforeSerialize);
//stream将university时间作为一个字符串显示,证明能正常工作
stream.Position = 0;
Console.WriteLine(new StreamReader(stream).ReadToEnd());
//反序列化universal时间字符串,并且把它转换成本地datetime
stream.Position = 0;
DateTime localTimeAfterDeserialize = (DateTime) formatter.Deserialize(stream);
//证明它能正确工作
Console.WriteLine("LocalTimeBeforeSerialize ={0}",localTimeBeforeSerialize);
Console.WriteLine("LocalTimeAfterDeserialize={0}",localTimeAfterDeserialize);
}
}
步骤1到步骤4执行完毕后,格式化器就准备好实用已登记的代理类型。调用格式化器的Serialize方法时,会在SurrogateSelector维护的集合(一个哈希表)中查找(要序列化的)每个对象的类型。如果发现一个匹配,就调用ISerializationSurrogate对象的GetObjectData方法来获取应该写入流的信息。
格式化器的Deseialize方法在调用时,会在格式化器的SurrogateSelector中查找要反序列化的对象的类型。如果发现一个匹配,就调用ISerializationSurrogate对象的SetObjectData方法来设置要反序列化的对象中的字段。
SurrogateSelector对象在内部维护了一个私有哈希表。调用AddSurrogate时,type和StreamingContext构成了哈希表的键(key),对应的值(value)就是ISerializationSurrogate对象。如果已经存在和要添加的Type/StreamingContext相同的一个键,AddSurrogate会抛出一个ArgumentException。通过在键中包含一个StramingContext,可以登记一个代理类型对象,它知道如何将Datetime对象序列化/反序列化到一个文件中;再登记一个不同的代理对象,它知道如何将Datetime对象序列化/反序列化到一个不同的进程中。

代理选择器链
多个SurrogateSelector对象可连接到一起。例如,可以让一个SurrogateSelector对象维护一组序列化代理,这些序列化代理(Surrogate)用于将类型序列化成代理(proxy),以便通过网络传送,或者跨越不同的AppDomain传送。还可以让另一个SurrogateSelector对象维护一组序列化代理,这些序列化代理用于将版本1的类型转换成版本2的类型。
Surrogate 代理: 负责序列化
proxy 代理: 负责跨越AppDomain边界访问对象


反序列化对象时重写程序集/类型
序列化对象时, 格式化器输出类型及其定义程序集的全名. 反序列化对象时, 格式化器根据这个信息确定要为对象构造并初始化什么类型. 前面讨论了如何利用ISerializationSurrogate接口来接管特定类型的序列化和反序列化工作, 实现了ISerializationSurrogate接口的类型与特定程序集中的特定类型关联.
有的时候ISerializationSurrogate机制的灵活性显得有点不足, 下面列举的情形中,有必要将对象反序列化成和序列化时不同的类型.
- 开发人员可能想把一个类型的实现从一个程序集移动到另一个程序集. 例如, 程序集的版本号的变化造成新程序集有别于原始程序集.
- 服务器对象序列化到发送给客户端的流中. 客户端处理流时, 可以将对象反序列化成完全不同的类型, 该类型的代码知道如何向服务器的对象发出远程方法调用.
- 开发人员创建了类型的新版本, 想把已序列化的对象反序列化成类型的新版本.
利用SerializationBinder类, 可以非常简单地将一个对象反序列化成不同类型. 为此,要先定义自己的类型, 让它从抽象类SerializationBinder类派生, 假定你的版本1.0.0.0程序集定义了名为Ver1的类, 并假定程序集的新版本定义Ver1ToVer2SerializationBinder类, 还定义了名为Ver2的类:
internal static class SerializationBinderDemo
{
public static void Go()
{
using (var stream = new MemoryStream())
{
IFormatter formatter = new BinaryFormatter();
formatter.Binder = new Ver1ToVer2SerializationBinder();
formatter.Serialize(stream, new Ver1());
stream.Position = 0;
Ver2 t = (Ver2) formatter.Deserialize(stream);
Console.WriteLine("反序列化:{0}, ToString={{{1}}}", t.GetType(), t);
}
}
[Serializable]
private sealed class Ver1
{
public Int32 x = 1, y = 2, z = 3;
}
[Serializable]
private sealed class Ver2 : ISerializable
{
Int32 a, b, c;
[SecurityPermissionAttribute(SecurityAction.Demand, SerializationFormatter = true)]
public void GetObjectData(SerializationInfo info, StreamingContext context)
{
/* Never called: do nothing */
}
// 特殊构造器
[SecurityPermissionAttribute(SecurityAction.Demand, SerializationFormatter = true)]
private Ver2(SerializationInfo info, StreamingContext context)
{
a = info.GetInt32("x");
b = info.GetInt32("y");
c = info.GetInt32("z");
}
public override string ToString()
{
return String.Format("a={0}, b={1}, c={2}", a, b, c);
}
}
private sealed class Ver1ToVer2SerializationBinder : SerializationBinder
{
public override void BindToName(Type serializedType, out string assemblyName, out string typeName)
{
assemblyName = Assembly.GetExecutingAssembly().FullName;
typeName = typeof(Ver2).FullName;
}
public override Type BindToType(String assemblyName, String typeName)
{
// 将任何Ver1对象从版本1.0.0.0反序列化成一个Ver2对象
// 计算定义Ver1类型的程序集名称
AssemblyName assemVer1 = Assembly.GetExecutingAssembly().GetName();
assemVer1.Version = new Version(1, 0, 0, 0);
// 如果从V1.0.0.0反序列化Ver1对象, 就把它转变成一个Ver2对象
if (assemblyName == assemVer1.ToString() && typeName == "SerializationBinderDemo+Ver1")
return typeof(Ver2);
// 否则, 就只返回请求的同一类型
return Type.GetType(String.Format("{0}, {1}", typeName, assemblyName));
}
}
}

