数组
CLR支持一维,多维和交错数组(数组构成的数组).
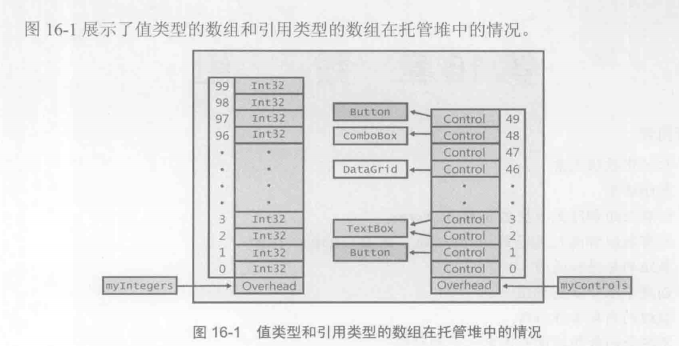
所有数组类型 隐式地从System.Array抽象类派生, System.Array又派生自System.Object. 数组 始终是引用类型, 是在托管堆上分配的.
// 刚开始声明变量, 没有分配数组,所以为null
Int32[] myInts; // 声明一个数组引用
// 在托管堆上分配了100个未装箱Int32所需的内存块,返回该内存块的地址
// 所有Int32都被初始化为0。因为数组是引用类型,
// 所以内存块中还包含类型对象指针,同步索引块,一些开销字段(额外成员)
myInts = new Int32[100]; //创建含有100个Int32的数组
Control[] myCon;
// Control是引用类型,50个引用全部被初始化为null
myCon = new Control[50];
// 执行一些代码
myCon[1] = new Button();
myCon[2] = new TextBox();
myCon[3] = myCon[2]; //两个元素引用同一个对象
myCon[1] = new DataGrid();
myCon[1] = new ComboBox();
myCon[1] = new Button();
所有数组必须是0基数组(最小索引为0). CLR支持非0基数组,只是不提倡使用,性能会下降.
每个数组都关联了一些额外的开销信息,
- 数组的秩(数组的维数).
- 数组的每一维的下限(几乎总是0)和每一维的长度.
- 数组的元素类型
应尽可能的使用一维0基数组,也称为SZ数组或向量. 向量性能是最佳的,因为可以使用一些特殊的IL指令.
// 创建一个二维数组,由Double值构成
Double[,] myDoubles = new Double[10,20];
// 创建一个三维数组,由String引用构成
String[,,] myStrings = new String[5,3,10];
//CLR还支持交错数组,即由数组构成的数组。下面例子演示了如何创建一个多边形数组,其中每一个多边形都由一个Point实例数组构成。
// 创建一个含有Point数组的一维数组
Point[][] myPolygons = new Point[3][];
// myPolygons[0]引用一个含有10个Point实例的数组
myPolygons[0] = new Point[10];
// myPolygons[1]引用一个含有20个Point实例的数组
myPolygons[1] = new Point[20];
// myPolygons[2]引用一个含有30个Point实例的数组
myPolygons[2] = new Point[30];
// 显示第一个多边形中的Point
for (Int32 x =0 ; x < myPolygons[0].Length; x++)
{
Console.WriteLine(myPolygons[0][x]);
}
访问数组范围之外的会导致System.IndexOutOfRangeException异常.
数组索引范围检查对性能的检查微乎其微,JIT编译器通常只在循环开始之前检查一次数组边界,而不是每次循环迭代都检查, 还可以用C#的unsafe代码来访问数组,规避这个CLR索引检查造成的性能损失.
初始化数组元素
大括号中的以逗号分隔的数据项称为数组初始化器,每个数据项都可以是一个复杂的表达式.
String[] names = new String[] { "Aidan", "Grant" };
C#的隐式类型的局部变量功能 var
隐式类型的局部变量功能, 让编译器推断=操作符右侧的表达式类型.
// 用var代替String
var names = new String[] { "Aidan", "Grant" };
C#的隐式类型的数组功能
隐式类型的数组功能让编译器推断数组元素的类型.省略了new和[]之间的类型.
// 省略了new和[]之间的类型
// 选择所有数组元素最接近的共同基类来作为数组的类型
// 本例中,2个string和一个null , 因为null可以隐式转型为任意盈余类型,所以编译器创建为String数组
var names = new[] { "Aidan", "Grant", null};
// 错误的, 因为这样编译器只能推断为共同基类Object
// 这会造成123数值类型进行隐式装箱, 这个操作代价高昂,所以要在编译时报错
// var names = new[] { "Aidan", "Grant", 123};
// 额外语法,还可以这么写, 省略new 和[] 和类型.
// 但是这种写法不允许使用var
String[] names = { "Aidan", "Grant" };
匿名类型 与 隐式类型的数组 与 隐式类型的局部变量组合使用
// 两个匿名类具有一致的结构, 表示有一个string类型的Name字段的类.
// 所以编译器知道这两个对象具有相同的类型
var kids = new[] { new { Name = "Aidan" }, new { Name = "Grant" }};
foreach(var kid in kids)
Console.WriteLine(kid.Name);
数组转型
对于元素为引用类型的数组,CLR允许将数组元素从一种类型隐式转型到另一种类型。为了成功转型,两个数组类型必须维数相等,而且从源类型到目标类型,必须存在一个隐式或显示转换。CLR不允许将值类型元素的数组转型为其他任何类型。(不过为了模拟实现这种效果,可利用Array.Copy方法创建一个新数组并在其中填充数据)。
Array.Copy方法是浅拷贝.
// 创建一个二维FileStream数组
FileStream[,] fs2dim = new FileStream[5, 10];
// 隐式转型为一个二维Object数组
Object[,] o2dim = fs2dim;
// 不能从二维数组转型为一维数组
//Stream[] s1dim = (Stream[]) o2dim;
// 显式转型为二维Stream数组
Stream[,] s2dim = (Stream[,]) o2dim;
// 显式转型为二维String数组
// 能通过编译,但在运行时会抛出异常,InvalidCastException
// String[,] st2dim = (String[,]) o2dim;
// 创建一个意味Int32数组(元素是值类型)
Int32[] i1dim = new Int32[5];
// 不能将值类型的数组转型为其他任何类型
// Object[] o1dim = (Object[]) i1dim;
// 创建一个新数组,使用Array.Copy将元数组中的每一个元素
// 转型为目标数组中的元素类型,并把它们复制过去
// 下面的代码创建一个元素为引用类型的数组,
// 每个元素都是对已装箱的Int32的引用 ←-------------------重点
Object[] o1dim = new Object[i1dim.Length];
Array.Copy(i1dim, o1dim, 0);
数组协变性,数组间转型
Array.Copy方法的处理:
- 将值类型的元素 装箱 为引用类型的元素
- 将引用类型的元素 拆箱 为值元素, 比如将Object[]复制到Int32[]中.
- 加宽CLR基元值类型, 比如将Int32[]元素复制到Double[]中
- 在两个数组之间复制时, 如果仅从数值类型证明不了两者的兼容性, (比如Object[]转型为IFormattable) 就需要对元素进行向下类型转换. 如果Object[]中的每个对象都实现了IFormattable,那么Copy方法就能执行.
向下类型转换: 把父类对象转为子类对象。
向上类型转换: 将子类对象转为父类对象。此处父类对象可以是接口。
// 定义实现了一个接口的值类型
internal struct MyValueType : IComparable
{
public int CompareTo(object obj)
{
throw new NotImplementedException();
}
}
public static void Main(string[] args)
{
// 创建包含值类型的数组
var src = new MyValueType[100];
// 创建接口引用数组
var comparables = new IComparable[src.Length];
// 使他们引用src数组元素的已装箱版本
Array.Copy(src,comparables,src.Length);
}
// 性能损失
String[] sa = new String[100];
Object[] oa = sa; // oa引用了一个String数组
oa[5] = "Jeff"; // 性能损失,CLR检查oa元素类型是不是String类型,检查通过
// 运行时抛出ArraryTypeMismatchException
// 因为CLR要保证赋值的合法性
oa[3] = 5; // 性能损失,CLR检查oa元素类型是不是Int32; 发现有错,会抛出异常
将数组从一种类型转换为另一种类型. 这种功能称为 数组协变性 (协变out). 会带来性能损失.
关于复制数组到另一个数组
Array.Copy方法
- 能正确处理内存的重叠区域
- 能在复制每个数组元素时进行必要的转换
- 拆箱装箱,向下类型转换
System.Buffer的BlockCopy方法.
- 它比
Array的Copy方法快. - 它只支持基元类型
- 不提供Copy方法那样的转型能力.
- 方法的Int32参数时数组中的字节偏移量,而非元素索引.
- 用于将Unicode字符的一个Byte[] (按字节的正确顺序) 复制到一个Char[]中.
要将一个数组的元素可靠地复制到另一个数组,应该使用System.Array的ConstrainedCopy.
- 该方法要么完成复制,要么抛出异常,总之不会破坏目标数组中的数据.
- 这就允许ConstrainedCopy在
约束执行区域中执行,为了这种保证- 要求
源数组的元素类型和目标数组的元素类型相同或者 派生自 目标数组的元素类型. - 不执行任何装箱,拆箱或向下类型转换.
- 要求
所有数组都隐式派生自System.Array
FileStream[] fsArray;
System.Array类型定义的所有实例方法和属性都将由FileStream[]继承.
所有数组都隐式实现IEnumerable, ICollection, IList
许多方法都能操纵各种各样的集合对象,因为它们声明为获取IEnumerable, ICollection, IList等参数. System.Array也实现了这些非泛型接口.
CLR没有为System.Array实现泛型接口,而是在创建一维0基数数组类型时,CLR自动使数组类型实现IEnumerable<T>, ICollection<T>, IList<T>,同时还为数组类型的所有基类型实现这三个接口,只要它们是引用类型(数组是值类型则不会).
FileStream[] fsArray; 会在CLR下产生如下结构:

fsArray可以传给以下任何一种原型方法:
void M1(IList<FileStream> fsList){...}
void M2(ICollection<Stream> sCollection){...}
void M3(IEnumerable<Object> oEnumerable){...}
如果数组包含值类型元素,数组类型不会为元素的基类型实现接口.例如:一个值类型数组DateTime[] dtArray; 只会为此数组类型实现3个泛型接口,CLR不会为它的基类包括ValueType,Object实现这些泛型接口. 这是因为值类型的数组在内存中的布局与引用类型的数组不同.
数组的传递和返回
数组作为实参传递给方法时, 传递的是数组的引用,如果不想被修改,则需要生成数组的拷贝给方法. Array.Copy方法执行是对原始数组的浅拷贝, 如果数组中的元素类型是引用类型,新数组还是引用现有的对象.
定义返回数组引用的方法, 如果数组中不包含元素, 不要返回null,建议返回对包含零个元素的一个数组的引用. 这这就不需要进行null检测. if (xxx != null) ...
创建下限非零的数组
可以调用数组的静态方法CreatInstance来动态的创建自己的数组. 允许指定数组的类型,维数,每一维的下限和每一维的元素数目.
静态方法CreatInstance为数组分配内存,将参数信息保存到数组的内存块的开销(overhead)部分,然后返回对该数组的引用.
- 如果维数是二维及以上,可以把返回的引用转型为一个
ElementType[]变量(名称替换为类型名称),来简化对数组元素的访问. - 如果是一维,C#要求必须使用该Array的GetValue和SetValue方法访问数组元素.
// 创建一个二维数组{2005...2009} {1...4}
Int32[] lowerBounds = {2005, 1};
Int32[] lengths = {5, 4};
// 传入元素的类型, 5行4列
Decimal[,] quarterlyRevenue = (Decimal[,])
Array.CreateInstance(typeof(Decimal), lengths, lowerBounds);
// Array的Rank 属性:得到Array的秩(维数) quarterlyRevenue.Rank等于2;
// GetUpperBound(int dimension) 用于获取 Array 的指定维度的上限。
// GetLowerBound(int dimension) 用于获取 Array 的指定维度的下限。
// 取得第一维的下限 , 如果传入1, 则表示取得第二维的下限
Int32 firstYear = quarterlyRevenue.GetLowerBound(0);
Int32 lastYear = quarterlyRevenue.GetUpperBound(0);
Console.WriteLine("{0,4} {1,9} {2,9} {3,9} {4,9}", "Year", "Q1", "Q2", "Q3", "Q4");
Random r = new Random();
for (Int32 year = firstYear; year <= lastYear; year++)
{
Console.Write(year + " ");
// 把二维数组看成表格,从(1,1)开始, 小于第二维的个数,横向遍历
for (Int32 quarter = quarterlyRevenue.GetLowerBound(1);
quarter <= quarterlyRevenue.GetUpperBound(1);
quarter++)
{
quarterlyRevenue[year, quarter] = r.Next(10000);
// C 表示格式化为货币
Console.Write("{0,9:C} ", quarterlyRevenue[year, quarter]);
}
Console.WriteLine();
}
// Year Q1 Q2 Q3 Q4
// 2005 ¥2,102.00 ¥7,295.00 ¥105.00 ¥5,846.00
// 2006 ¥6,331.00 ¥1,955.00 ¥879.00 ¥8,752.00
// 2007 ¥912.00 ¥1,105.00 ¥6,960.00 ¥7,205.00
// 2008 ¥6,479.00 ¥6,034.00 ¥6,182.00 ¥3,565.00
// 2009 ¥558.00 ¥8,291.00 ¥4,028.00 ¥1,740.00
数组内部的工作原理
CLR支持两种不同的数组:
- 下限为0的一维数组或向量
- 下限未知的一维或多维数组
Array a;
// 定义一维的0基数组,不包含任何元素
a = new String[0];
Console.WriteLine(a.GetType()); // System.String[]
// 定义一维的0基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] {0}, new Int32[] {0});
Console.WriteLine(a.GetType()); // System.String[]
// 定义一维的1基数组,不包含任何元素
// 1基数组显示的类型是System.String[*], *号表示CLR知道该数组不是0基的.
// C#不允许声明String[*]类型的变量,因此不能使用C#语法来访问一维非0基数组.
// 可以用Array的GetValue和SetValue来访问,但是速度较慢,调用方法有开销.
a = Array.CreateInstance(typeof(String), new Int32[] {0}, new Int32[] {1});
Console.WriteLine(a.GetType()); // System.String[*] <-- INTERESTING!
// 定义二维的0基数组,不包含任何元素
a = new String[0, 0];
Console.WriteLine(a.GetType()); // System.String[,]
// 定义二维的0基数组,不包含任何元素
a = Array.CreateInstance(typeof(String), new Int32[] {0, 0}, new Int32[] {0, 0});
Console.WriteLine(a.GetType()); // System.String[,]
// 定义二维的1基数组,不包含任何元素
// CLR会将多维数组都视为非0基数组,CLR决定对多维数组不使用*号
a = Array.CreateInstance(typeof(String), new Int32[] {0, 0}, new Int32[] {1, 1});
Console.WriteLine(a.GetType()); // System.String[,]
- 1基数组显示的类型是
System.String[*],*号表示CLR知道该数组不是0基的. - C#不允许声明
String[*]类型的变量,因此不能使用C#语法来访问一维非0基数组. - 可以用Array的GetValue和SetValue来访问,但是速度较慢,调用方法有开销.
对于多维数组,CLR会将多维数组都视为非0基数组,会让别人觉得类型是这样System.String[*,*],但是CLR决定对于多维数组,不使用*号,大量星号容易产生混淆.
访问1维0基数组的元素比访问非0基一维或多维元素稍快.
- 有特殊的IL指令用于处理0基数组,可以让JIT编译器生成优化代码
- JIT编译器生成的代码假定数组是0基的,访问元素时不需要从指定索引中减去一个偏移量
- JIT编译器能将索引范围检查代码从循环中拿出,导致它只执行一次
var ints = new Int32[5];
// ints.Length调用属性方法
for (int i = 0; i < ints.Length; i++)
{
// 对ints[i]操作
}
JIT编译器知道Length是Array类的属性,所以生成的代码中实际只调用该属性一次,结果保存到临时变量中 , 之后的每次迭代检查的都是这个临时变量,这就加快了JIT编译的代码速度.
因此,最好保持对数组Length属性的调用,而 不要自己用什么局部变量来缓存它的值. 这种自作聪明的尝试几乎肯定会对性能造成负面影响,还会使代码更难阅读.
JIT编译器知道for循环要访问0到Length-1的数组元素,JIT编译器会生成代码,在运行时测试所有数组元素的访问都在有效范围内.
- 也就是来检查是否
(0 >= ints.GetLowerBound(0)) && ((Length -1)) <= ints.GetUpperBound(0) - 这个检查在循环之前发生,如果都在有效范围内,JIT编译器不会在每一次数组访问时再检查验证. 这样一来访问变得非常快.
对于非0基数组和多维数组,JIT编译器不会将索引检查从循环中拿出来,所以每次访问都要验证指定的索引.导致访问速度比不上一维0基数组. 还要添加代码从指定索引中减去数组下限,进一步影响了代码执行速度.
如果很关心性能. 考虑用由数组构成的数组(交错数组)代替矩形数组.
C#和CLR还允许使用unsafe代码访问数组.这种技术实际能在访问数组时关闭索引上下限检查.
- 适用于以下元素类型的数组:
- SByte,Byte,Int16,UInt16,Int32,UInt32,Int64,UInt64,Char,Single,Double,Decimal,Boolean,枚举类型或任何类型的值类型结构.
这个功能很强大,但是使用需要谨慎,它允许直接内存访问,访问越界不会抛出异常.但会损坏内存中的数据.破坏类型的安全性.
访问二维数组的三种方式(安全,交错和不安全):
private const Int32 c_numElements = 10000;
public static void Go()
{
// 声明二维数组
Int32[,] a2Dim = new Int32[c_numElements, c_numElements];
// 将二维数组声明为交错数组
Int32[][] aJagged = new Int32[c_numElements][];
for (Int32 x = 0; x < c_numElements; x++)
aJagged[x] = new Int32[c_numElements];
// 1: 用普通的安全技术访问数组中的所有元素
// 二维数组对象 a[x, y];
Safe2DimArrayAccess(a2Dim);
// 2: 用交错数组技术访问数组中的所有元素
// 交错数组对象 a[x][y]
SafeJaggedArrayAccess(aJagged);
// 3: 用unsafe技术访问数组中的所有元素
Unsafe2DimArrayAccess(a2Dim);
}
private static Int32 Safe2DimArrayAccess(Int32[,] a)
{
Int32 sum = 0;
for (Int32 x = 0; x < c_numElements; x++)
{
for (Int32 y = 0; y < c_numElements; y++)
{
sum += a[x, y];
}
}
return sum;
}
private static Int32 SafeJaggedArrayAccess(Int32[][] a)
{
Int32 sum = 0;
for (Int32 x = 0; x < c_numElements; x++)
{
for (Int32 y = 0; y < c_numElements; y++)
{
sum += a[x][y];
}
}
return sum;
}
// fixed 语句必须要用unsafe方法修饰符
private static unsafe Int32 Unsafe2DimArrayAccess(Int32[,] a)
{
Int32 sum = 0, numElements = c_numElements * c_numElements;
fixed (Int32* pi = a)
{
for (Int32 x = 0; x < numElements; x++)
{
sum += pi[x];
}
}
return sum;
}
不安全数据访问技术的三处不足之处:
- 处理数组元素的代码更复杂,不容易读写,因为要使用C#的
fixed语句,要执行内存地址计算. - 计算过程出错,会损坏内存数据,破坏类型安全性,并可能造成安全漏洞.
- 因为这些潜在问题,CLR禁止在降低了安全级别的环境中运行不安全代码.
单维数组
// 可以在声明时初始化数组,在这种情况下,无需长度说明符,因为它已由初始化列表中的元素数目提供。
// 并且可以省略new int[]
int[] array1 = new int[] { 1, 3, 5, 7, 9 };
int[] array2 = { 1, 3, 5, 7, 9 };
// 可以在不初始化的情况下声明数组变量,但必须使用 new 运算符向此变量分配数组。
int[] array3;
array3 = new int[] { 1, 3, 5, 7, 9 }; // OK
//array3 = {1, 3, 5, 7, 9}; // Error
多维数组
二维数组,逗号分隔,几行几列.
// 以下声明创建一个具有四行两列的二维数组。
// 也可以
int[,] array = new int[4, 2];
// 三维数组
int[, ,] array1 = new int[4, 2, 3];
// Two-dimensional array.
int[,] array2D = new int[,] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
// The same array with dimensions specified.
int[,] array2Da = new int[4, 2] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
// A similar array with string elements.
string[,] array2Db = new string[3, 2] { { "one", "two" }, { "three", "four" },
{ "five", "six" } };
// 可以简化写法
int[,] array4 = { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } };
// 如果选择在不初始化的情况下声明数组变量,则必须使用 new 运算符将数组赋予变量。
int[,] array5;
array5 = new int[,] { { 1, 2 }, { 3, 4 }, { 5, 6 }, { 7, 8 } }; // OK
//array5 = {{1,2}, {3,4}, {5,6}, {7,8}}; // Error
// 以下代码示例将数组元素初始化为默认值(交错数组除外)
int[,] array6 = new int[10, 10];
交错数组
交错数组是元素为数组的数组。 交错数组元素的维度和大小可以不同。 交错数组有时称为“数组的数组”
// 声明三个元素,每个元素都是一维整数数组
int[][] jaggedArray = new int[3][];
// 必须初始化 jaggedArray 的元素后才可使用它。
jaggedArray[0] = new int[5];
jaggedArray[1] = new int[4];
jaggedArray[2] = new int[2];
// 也可使用初始化表达式通过值来填充数组元素,这种情况下不需要数组大小
jaggedArray[0] = new int[] { 1, 3, 5, 7, 9 };
jaggedArray[1] = new int[] { 0, 2, 4, 6 };
jaggedArray[2] = new int[] { 11, 22 };
// 不能从元素初始化中省略 new 运算符,因为不存在元素的默认初始化:
// 可以省略 new int[][]
int[][] jaggedArray3 = // new int[][]
{
new int[] { 1, 3, 5, 7, 9 },
new int[] { 0, 2, 4, 6 },
new int[] { 11, 22 }
};
// 混合使用多维数组和交错数组
int[][,] jaggedArray4 = new int[3][,]
{
new int[,] { {1,3}, {5,7} },
new int[,] { {0,2}, {4,6}, {8,10} },
new int[,] { {11,22}, {99,88}, {0,9} }
};
// 访问个别元素,示例显示第一个数组的元素 [1,0] 的值
System.Console.Write("{0}", jaggedArray4[0][1, 0]);// 5
// 方法 Length 返回包含在交错数组中的数组的数目
System.Console.WriteLine(jaggedArray4.Length); // 3
对数组使用foreach
- 对于单维数组,foreach 语句以递增索引顺序处理元素(从索引 0 开始并以索引 Length - 1 结束)
- 对于多维数组,遍历元素的方式为:首先增加最右边维度的索引,然后是它左边的一个维度,以此类推,向左遍历元素
// 一维数组的foreach
int[] numbers = { 4, 5, 6, 1, 2, 3, -2, -1, 0 };
foreach (int i in numbers)
{
System.Console.Write("{0} ", i);
}
// Output: 4 5 6 1 2 3 -2 -1 0
// 多维数组的foreach
int[,] numbers2D = new int[3, 2] { { 9, 99 }, { 3, 33 }, { 5, 55 } };
//省略 new int[3, 2]写法
//int[,] numbers2D = { { 9, 99 }, { 3, 33 }, { 5, 55 } };
foreach (int i in numbers2D)
{
System.Console.Write("{0} ", i);
}
// Output: 9 99 3 33 5 55
不安全的数组访问和固定大小的数组
不安全的数组访问能力非常强大,因为它允许访问:
堆上的托管数组对象中的元素非托管堆上的数组中的元素.(14章的ScureString演示了调用Marshal类的SerureStringToCoTaskMemUnicode方法来返回一个数组,并对这个数组进行不安全的数组访问)线程栈上的数组中的元素
如果考虑性能是首要目标,请避免在堆上分配托管的数组对象.在线程栈上分配数组. 这是通过C#的stackalloc语句来完成的. 并且只能创建一维0基,由值类型元素构成的数组. 值类型中不能包含任何引用类型的字段. 实际上可以看做是分配了一个内存块,这个内存块可以使用不安全的指针来操作. 所以不能将这个内存缓冲区的地址传给大部分FCL方法. 栈上分配的内存会在返回时自动释放.
private static void StackallocDemo()
{
unsafe
{
const Int32 width = 20;
// 在栈上分配数组
Char* pc = stackalloc Char[width];
// 15 个字符
String s = "Jeffrey Richter";
for (Int32 index = 0; index < width; index++)
{
pc[width - index - 1] =
(index < s.Length) ? s[index] : '.';
}
// 输出 ".....rethciR yerffeJ"
Console.WriteLine(new String(pc, 0, width));
}
}
private static void InlineArrayDemo()
{
unsafe
{
// 在栈上分配数组
CharArray ca;
Int32 widthInBytes = sizeof(CharArray);
Int32 width = widthInBytes / 2;
// 15 个字符
String s = "Jeffrey Richter";
for (Int32 index = 0; index < width; index++)
{
ca.Characters[width - index - 1] =
(index < s.Length) ? s[index] : '.';
}
// 输出 ".....rethciR yerffeJ"
Console.WriteLine(new String(ca.Characters, 0, width));
}
}
private unsafe struct CharArray
{
// 这个数组内联嵌入到结构中
public fixed Char Characters[20];
}
由于数组是引用类型,所以结构中定义的数组字段实际只是指向数组的指针或引用. 数组本身在结构的内存的外部. 不过可以像上述代码public fixed Char Characters[20]; 嵌入到结构中,但是需要满足以下条件:
- 类型必须是
结构(值类型); 不能再类(引用类型)中嵌入数组. - 字段或其定义结构必须用
unsafe关键字标记 - 数组字段必须用
fixed关键字标记. - 数组必须是一维0基数组.
- 数组的元素类型必须是以下类型之一:
- Char,SByte,Byte,Int16,UInt16,Int32,UInt32,Int64,UInt64,Char,Single,Double,Boolean
要和非托管代码进行互操作,而且非托管数据结构也有一个内联数组,就特别适合使用内联的数组.
