字符,字符串和文本处理
Micorsoft .Net Framework中处理字符和字符串的机制.
System.Char结构以及处理字符的多种方式.System.String处理不可变(immutable)字符串(一旦创建,字符串便不能以任何方式修改).System.Text.StringBuilder高效的动态构造字符串.- 如何将对象格式化成字符串, 以及如何使用各种编码方案高效率的持久化或传输字符串.
System.Security.SecureString保护密码等敏感字符串.
字符
在.Net Framework中字符总是表示成 16位的Unicode代码值.
每个字符都是一个System.Char结构(值类型)的实例. 并提供了两个公共只读常量字段:
MinValue:'\0'MaxValue:'\ufff'
Unicode标准定义了控制字符,货币字符,小写字母,大写字母,标点符号,数学符号还有其他符号. System.Globalization.UnicodeCateGory枚举定义了这些枚举类型. Char的实例调用静态方法GetUnicodeCategory方法返回这些枚举中的一个值. 反应这个字符是什么种类的.
Char类型其他几个静态方法,大多数都在内部调用GetUnicodeCategory方法,并简单的返回true/false.
这些方法要么获取当字符作为参数,要么获取String以及目标字符在这个String中的索引作为参数.
关于语言文化culture, 有些方法比如ToLowerInvariant会以忽略语言文化的方式将字符转换为小写.
比如土耳其语中,字母U+0069(小写拉丁字母i)转换成大写是U+0130(大写拉丁字母I上加一点).
Char类型自己的实例方法:
Equals: 两个Char实例代表同一个16位Unicode码位的前提下返回true. (ASCII码包含128个码位)CompareTo: 返回两个Char实例忽略语言文化的比较结果.ConvertFromUtf32: 从UTF-32字符生成包含1个或2个UTF-16字符的字符串ConvertToUtf32: 从字符串生成一个UTF-32字符ToString: 返回单个字符的一个String, 相反的是Parse/TryParse,它们获取单字符的String,返回该字符的UTF-16码位.GetNumericValue: 返回字符的数值形式.
// 返回字符的数值形式
Double d = Char.GetNumericValue('\u0033'); // \u0033 是数字3
Console.WriteLine(d.ToString()); // 输出: 3
d = Char.GetNumericValue('\u00bc'); // \u00bc 是普通分数的1/4
Console.WriteLine(d.ToString()); // 输出: 0.25
d = Char.GetNumericValue('A');
Console.WriteLine(d.ToString()); // 输出: -1
三种技术实现数值类型与Char实例的互相转换. 按照优先顺序列出:
- 转型(强制类型转换)
- 比如将Char转换成数值Int32最简单的办法就是强制转换. 这是三种技术中 效率最高的,因为编译器会生成中间语言IL指令执行转换,而且不必调用方法. 需要考虑转换时是否使用
checked还是unchecked(对基元类型执行的许多算术运算符都可能造成溢出).
- 比如将Char转换成数值Int32最简单的办法就是强制转换. 这是三种技术中 效率最高的,因为编译器会生成中间语言IL指令执行转换,而且不必调用方法. 需要考虑转换时是否使用
- 使用
Convert类型System.Convert类型提供了几个静态方法实现Char和数值类型的相互转换,所有这些转换都以checked方式执行,发现转换将造成数据丢失就抛出OverflowException异常.
- 使用
IConvertible接口Char类型和FCL中的所有数值类型都实现了IConvertible接口. 这个接口定义了像ToUInt16和ToChar这样的方法. 这种效率最差,因为值类型调用接口方法会产生装箱, Char和所有数值类型都是值类型. 所以许多类型(包括FCL的Char和数值类型)都将IConvertble的方法实现了 EIMI显式接口方法成员. 这就意味着为了调用接口的任何方法,都必须将实例显式转型为一个IConvertible接口变量, 转换时,大多数时候都可以忽略语言文化,为IFormatProvider这个参数传递null值.
public static void Main()
{
Char c;
Int32 n;
// 使用C#转型技术实现,强制类型转换
// 效率最高,直接编译生成中间语言IL指令执行转换
// 需要考虑是否会溢出,对基元类型执行的许多算术运算符都可能造成溢出
// 转换时是否使用`checked`还是`unchecked`
c = (Char)65;
Console.WriteLine(c); // 显示 "A"
n = (Int32)c;
Console.WriteLine(n); // 显示 "65"
c = unchecked((Char)(65536 + 65));
Console.WriteLine(c); // 显示 "A"
// 使用Convert进行转换
// 这些转换方法都以checked方式执行
// 转换出现数据丢失会抛出异常
c = Convert.ToChar(65);
Console.WriteLine(c); // 显示 "A"
n = Convert.ToInt32(c);
Console.WriteLine(n); // Displays "65"
// 显示Convert的范围检查
try {
// 2^16 = 65535
c = Convert.ToChar(70000); // 对 16-bits 来说过大,转换丢失精度
Console.WriteLine(c); // !!!不执行
}
catch (OverflowException) {
Console.WriteLine("Can't convert 70000 to a Char.");
}
// 使用IConvertible进行转换
// 效率最差,因为值类型调用接口方法会产生装箱(Char和所有数值类型都是值类型)
// IConvertble的方法实现了 EIMI显式接口方法成员,所以要转换成接口类型变量才能调用接口方法
// 传递参数IFormatProvider为null 是忽略语言文化
c = ((IConvertible)65).ToChar(null);
Console.WriteLine(c); // 显示 "A"
n = ((IConvertible)c).ToInt32(null);
Console.WriteLine(n); // 显示 "65"
}
System.String类型
一个System.String代表一个不可变(immutable)的顺序字符集.
String是引用类型, 对象总是存在于堆上,永远不会到线程栈.
构造字符串
C#将String视为基元类型, 编译器允许在源代码中直接使用字面值(literal)字符串, 编译器将这些字符串放到模块的元数据中,并在运行时加载和引用它们.
- 不允许用new操作符从字面值字符串构造String对象.
// 不能使用 new + 字面值(literal)字符串 构造.
String s = new String("Error");// 错误
// 必须使用简化语法
String s = "Hi there.";

用于构造对象新实例的IL指令时newobj. 但是上述IL代码中并没出现这个指令, 出现的是ldstr(load string)指令, 它使用从元数据获得的字面值literal字符串构造String对象.这证明了CLR实际用一种特殊的方式构造字面值String对象.
如果使用不安全的unsafe代码,可以从一个Char*或Sbyte*构造一个String. 这时要使用到new操作符,调用对应参数的构造器.
C#提供了一些特殊语法来帮助开发人员在源代码中输入字面值字符串. 对于换行符,回车符和退格符这样的特殊字符,采用如下转义机制:
// 这是硬编码了回车符和换行符,一般不建议这样做
// 不同底层平台使用的不一定相同
// \r 回车符 \n 换行符
String s = "Hi\r\nthere.";
// 正确定义上述字符串的方式
// Environment.NewLines属性对平台敏感, 会根据平台返回恰当的字符串
String s = "Hi" + Environment.NewLine + "there.";
使用+操作符可以将几个字符串连接成一个, 如果都是字面值,C#编译器在编译时就能连接它们,最终将一整个字符串放到模块的元数据中, 如果存在非字面值,则会在运行时进行.
运行时连接不建议使用+操作符, 这样会在堆上创建多个字符串对象,而堆是需要垃圾回收的,对性能有影响. 应该使用StringBuilder类型.
逐字字符串声明(@ 操作符)
采用这种方法,引号之间的所有字符都会视为字符串的一部分, 也就是不转义\,视为字符串, 通常用于指定文件和目录的路径,或者与正则表达式配合使用.
// 不使用@逐字字符串声明方式
String s = "C:\\Window\\System32\\Notepad.exe";
// 使用@方式
String s = @"C:\Window\System32\Notepad.exe";
两种写法在程序集的元数据中生成完全一样的字符串,但是后者可读性更好.
字符串是不可变的
String对象最重要的一点就是不可变,并且只能是密封类. 一经创建便不能更改(变长,变短,修改任何字符).
好处有:
- 在字符串上执行各种操作,而不实际地更改字符串. 返回修改后的新建的字符串地址.
- 在操作字符串时不会发生线程同步问题.
字符串留用:CLR通过一个String对象共享多个完全一致的String内容,减少系统中的字符串数量,从而节省内存.
比较字符串
判断相等性或者排序. 建议调用String类定义的一下方法:
// 建议使用以下版本, 不建议使用没有列出的重载版本
bool Equals (string value, StringComparison comparisonType);
static bool Equals (string a, string b, StringComparison comparisonType);
static int Compare (string strA, string strB, StringComparison comparisonType);
static int Compare (String strA, String strB, bool ignoreCase, CultureInfo culture);
static int Compare (string strA, string strB, CultureInfo culture, CompareOptions options);
static int Compare (string strA, int indexA, string strB, int indexB, int length, StringComparison comparisonType);
static int Compare (string strA, int indexA, string strB, int indexB, int length, CultureInfo culture, CompareOptions options);
static int Compare (String strA, int indexA, String strB, int indexB, int length, bool ignoreCase, CultureInfo culture);
比较时应该区分大小写, 原因是两个大小写不同的字符串会被视为相等.
建议避免使用 String实现IComparable接口的CompareTo方法, CompareOrdinal方法, ==操作符, !=操作符. 这是因为调用者不显式指出以什么方式执行字符串比较, 比如CompareTo方法默认执行语言文化敏感的比较, 而Equals方法执行 不考虑语言文化的序号(ordinal)比较.
Ordinal: 序号比较, 就是不考虑语言文化信息, 只比较字符串中每个Char的Unicode码位.
comparisonType参数,要求获取StringComparison枚举定义的某个值:
// 要求传递显式传递语言文化
public enum StringComparison
{
// 为了向用户显式一些字符串,要以语言文化正确的方式,就应该使用如下两个,
//使用区域敏感排序规则和当前区域比较字符串。
CurrentCulture,
//使用区域敏感排序规则、当前区域来比较字符串,同时忽略被比较字符串的大小写。
CurrentCultureIgnoreCase,
// ----------------------
// 平时不建议使用,所花的时间远超Ordinal
//使用区域敏感排序规则和固定区域比较字符串。
InvariantCulture,//固定语言文化 --- 其实就是不使用任何具体的语言文化.
//使用区域敏感排序规则、固定区域来比较字符串,同时忽略被比较字符串的大小写。
InvariantCultureIgnoreCase,
// ----------------------
// 以下选项会忽略语言文化(常用)
// 特别是在程序内部使用的字符串, 比如文件名,URL,注册表值,环境变量,反射,XML标记,特性等.
// 忽略语言文化是字符串比较最快的方式
//使用序号排序规则比较字符串。
Ordinal,
//使用序号排序规则并忽略被比较字符串的大小写,对字符串进行比较。
OrdinalIgnoreCase
}
要在比较前更改字符串中的字符的大小写, 应该使用:
String.ToUpperInvariant, 强烈建议使用此方法对字符串进行正规化(normalizing),不使用转小写String.ToLowerInvariant, 建议使用.
因为Microsoft对执行大写比较的代码进行了优化. , 事实上,执行不区分大小写的比较之前, FCL会自动将字符串正规化为大写形式.
之所以使用ToUpperInvariant和ToLowerInvariant,是因为String类没有提供ToUpperOrdinal和ToLowerDordinal方法, 不使用以下2个方法是因为以下方法对语言文化敏感.
String.ToUpper(不建议使用,因为对语言文化敏感)String.ToLower(不建议使用,因为对语言文化敏感)
CompareOptions参数。这个参数要获取有CompareOptions枚举类型定义的一个值:
public enum CompareOptions
{
None = 0,
//指示字符串比较必须忽略大小写。
IgnoreCase = 1,
//指示字符串比较必须忽略不占空间的组合字符,比如音调符号。
IgnoreNonSpace = 2,
//指示字符串比较必须忽略符号,如空白字符、标点符号、货币符号、百分号、数学符号、“&”符等等
IgnoreSymbols = 4,
//指示字符串比较必须忽略 Kana 类型
IgnoreKanaType = 8,
//指示字符串比较必须忽略字符宽度
IgnoreWidth = 16,
//指示字符串比较必须使用字符串排序算法。
StringSort = 0x20000000,
//指示必须使用字符串的连续 Unicode UTF-16 编码值进行字符串比较(使用代码单元进行代码单元比较),这样可以提高比较速度,但不能区分区域性
Ordinal = 0x40000000,
//字符串比较必须忽略大小写,然后执行序号比较。
OrdinalIgnoreCase = 0x10000000
}
执行语言文化正确的比较
.Net Framework 使用 System.Globalization.CultureInfo 类型表示一个”语言/国家”.
- en-US 美国英语
- en-AU 澳大利亚英语
- de-DE 德国德语
在CLR中,每个线程都关联了两个特殊属性, 每个属性都应用一个CultureInfo对象:
CurrentUICulture: 该属性获取要向用户显示的资源. 在GUI或web窗体应用程序中特别有用.CurrentCulture:不适合CurrentUICulture属性的场合就用该属性.通过控制面板的区域和语言对话框来修改这个值.

如果不是序号比较(不考虑语言文化),就会进行字符展开,也就是将一个字符展开成忽视语言文化的多个字符. 这样比较字符串就

String s1 = "Strasse";
String s2 = "Straße"; // ß 等同于ss
// 忽略语言文化
Console.WriteLine(String.Compare(s1,s2,StringComparison.Ordinal)); // 两个字符串不同 输出 -108
CultureInfo ci = new CultureInfo("de-DE");
// 设置德语文化
Console.WriteLine(String.Compare(s1,s2,true,ci)); // 两个字符串相同 输出 0
关于法语,日语,一些比较参考书中代码. P289页
源代码不要用ANSI格式保存,否则日语字符会丢失,要保存的话选择另存为-并选择Unicode(UTF-8带签名)-代码页65001 , 这样C#编译器就能成功解析这个源文件代码了.
字符串留用
检查字符串相等性的操作,也可能是损害性能的操作,
- 执行
序号(ordinal 语言文化不敏感)相等性检查时- CLR快速检测两个字符串是否包含相同数量的字符
- 不相同则肯定不等.
- 若相同,CLR必须比较每个单独的字符才能最终确认
- CLR快速检测两个字符串是否包含相同数量的字符
- 执行
语言文化敏感的比较时:- CLR必须比较所有单独的字符(因为两个字符串长度不同也可能相等)
在内存中复制一个字符串的多个实例纯属浪费. 浪费内存,只需要保留一个实例,将引用字符串的所有变量执行单独一个字符串对象.
如果应用程序经常对字符串进行区分大小写的序号比较,或者事先知道许多字符串对象都有相同的值, 既可以用CLR的字符串留用(intering)机制来显著提升性能.
- CLR初始化会创建一个
内部哈希表.key:字符串 value:堆中对String对象的引用 - String提供了两个方法,访问这个内部哈希表
pulic static String Intern(String str);- 在内部哈希表中检查是否有匹配的,
- 如果存在,就返回对现有String对象的引用
- 如果不存在,就创建字符串副本,返回副本的引用
pulic static String IsInterned(String str);- 和上述方法一样,不同的是如果没有找到匹配的字符串
- 就会返回
null,不会将字符串添加到哈希表中.
垃圾回收器不能回收被内部哈希表所引用的字符串. 除非卸载AppDomain或进程终止.否则内部哈希表引用的String对象不能被释放.
(不要依赖这个行为)CLR在程序集加载时,默认留用程序集的元数据中描述的所有字面值字符串.
- CLR的4.5版本上,会忽略编译器的CompilationRelaxations和NoStirngInterning特性和标志.
- 以至于CLR会对字面值字符创进行留用.(事实上用NGen.exe编译,CLR4.5版本确实会使用这些特性)
- 所以不要依赖这个行为.
// 不要以字符留用为前提来写代码
// 即使指定了特性和标志,也可能进行字段留用,
String s1 = "Hello";
String s2 = "Hello";
// 没进行留用,则2个字符串是不同的堆对象
Console.WriteLine(Object.ReferenceEquals(s1,s2)); // 一些特定版本,不进行字段留用,这边就会返回false
s1 = String.Intern("Hello");
s2 = String.Intern("Hello");
// 显式调用字段留用之后, 以下输出就保证为true
Console.WriteLine(Object.ReferenceEquals(s1,s2));// 显式留用此字符串
字符串留用提升性能并减少内存消耗
// 方式一:
// 不利用字符串留用, 使用Equals忽略语言文化进行比较
// 将word和String数组中的字符串比较
private static Int32 NumTimesWordApperasEquals(String word, String[] wordlist)
{
Int32 count = 0;
for (int wordnum = 0; wordnum < wordlist.Length; wordnum++)
{
// Ordinal序号比较(忽略语言文化)
// 比较字符串内的各个单独字符,这个比较可能很慢
// wordlist可能含有多个元素引用了含有相同内容的不同String对象,并且不会被垃圾回收掉重复的
if (word.Equals(wordlist[wordnum], StringComparison.Ordinal))
{
count++;
}
}
return count;
}
// 方式二:
// 利用字符串留用的机制,使用ReferenceEquals比较
// 这个方法假定wordlist中的所有数组元素都引用已留用的字符串
private static Int32 NumTimesWordApperasIntern(String word, String[] wordlist)
{
word = String.Intern(word);
Int32 count = 0;
for (int wordnum = 0; wordnum < wordlist.Length; wordnum++)
{
if (Object.ReferenceEquals(word,wordlist[wordnum]))
{
count++;
}
}
return count;
}
方式二假定wordlist包含对已留用字符串的引用. 如果字符串出现多次,堆中只有一个String对象. 比较指针就能知道指定单词是否在数组中.
方式二的前提,是对需要留用的字符串进行留用(花费一些时间性能),应用程序总体性能是可能变慢的. 在多次要调用比较wordlist的情况下, 字符串留用是很有用的,但是使用需要谨慎. 这也是C#编译器默认不想启用字符串留用的原因.(虽然编译器应用特性并设置了不进行字符串留用的标志,但是CLR选择忽略这些设置你也没办法.)
字符串池
编译源代码时, 编译器会处理每个字面值字符串, 并在托管模块的元数据中嵌入.
如果同一个字符串在源代码中多次出现,都嵌入元数据会使生成的文件无谓地增大.
为了解决这个,C#编译器只在模块的元数据中只将字符串写入一次,引用该字符串的代码都被修改成引用元数据中的同一个字符串. 编译器能将单个字符的多个实例合并成一个实例,能显著减少模块的大小.
检查字符串中的字符和文本元素
检查字符串中的字符,String类型为此提供了几个属性和方法, 包括Length,Chars(有参属性,C#索引器),IndexOf,Contains,LastIndexOf…
文本元素(抽象字符): 有的抽象Unicode字符是两个码值的组合.
有的Unicode文本元素要求用两个16位值表示,
- 第一个称为
高位代理项(high surrogate)U+D800到U+DBFF之间 - 第二个称为
低位代理项(low surrogate)U+DC00到U+DFFF之间
有了代理项,Unicode就能表示100万个以上不同的字符.
为了正确处理文本元素,应当使用System.Globalization,StringInfo类型,
- 向此类的构造器传递一个字符串
- 查询
StringInfo的LengthTextElements属性来了解有多少个文本元素. - 接着使用
StringInfo的SubstringByTextElements方法来提取所有的文本元素.
StringInfo的静态方法GetTextElementEnumerator返回TextElementEnumerator对象,允许枚举字符串中包含的所有抽象Unicode字符.
StringInfo的静态方法ParseCombiningCharacers来返回一个Int32数组.从数组长度就能知道字符串包含多少个文本元素,每个数组元素都是一个文本元素的起始码值索引.


其他字符串操作

Clone返回同一个对象(this)的引用.
Copy返回指定字符串的新副本.引用(指针不同).
Substring返回代表原始字符串一部分的新字符串.
ToString返回对同一个对象(this)的引用.
因为字符串你是不可变的,所以返回的都是新字符串的引用.(除非使用不安全代码)
高效率构造字符串
可将StringBuilder看成是创建String对象的特殊构造器.
从逻辑上看, StringBuilder对象包含一个字段, 该字段引用了由Char结构构成的数组.可利用StringBuilder的各个成员来操纵该字符数组, 高效率地缩短字符串或更改字符串中的字符.
如果字符串变大了,超过了事先分配的 数组大小 , StringBuilder会自动分配一个新的,更大的数组, 复制字符,并开始使用新数组. 前一个数组被垃圾回收.
用StringBuilder构造好字符串后, 调用ToString方法既可以将StringBuilder的 字符数组 转换成String. 这样会在堆上新建String对象,堆上还有StringBuilder中的字符数组,可以继续处理StringBuilder种的字符数组,再次调用ToString把它转换成另一个String对象.
构造StringBuilder对象
大多数语言都不将StringBuilder视为基元类型. 要像构造其他任何非基元类型那样构造StringBuilder对象.
StringBuilder提供了许多构造器. 一些关键概念如下:
- 最大容量
- 一个Int32值,指定了能放到字符串中的最大字符数,默认是Int32.MaxValue(约20亿). 一般不用更改这个值. 有时需要指定较小的最大容量以确保不会创建超出特定长度的字符串,构造好之后就固定下来了,不能再变.
- 容量
- 一个Int32值, 指定了StringBuilder维护的字符数组的长度,默认16, 如果事先知道要放入多少,则应该在构造StringBuilder对象时自己设置容量.
- 在向字符数组追加字符时, StringBuilder会检测数组会不会超过设定的容量.如果会,StringBuilder会自动 倍增容量字段(翻倍). 旧的数组字符数组复制到新的数组中,随后
原始数组可以被垃圾回收. 数组动态扩展会损害性能,可以在构造时就设置一个合适的初始容量.
- 字符数组
- 一个由Char结构构成的数组, 负责维护字符串的字符内容.
- 可以用
StringBuilder的Length属性来获取已经使用的字符数. - 在构造时传递一个String来初始化数组.
- 不传递任何字符串,数组中就不包含任何字符,Length为0.
StringBuilder成员
StringBuilder代表可变字符串, 大多数成员都能更改字符数组的内容, 同时不会造成在托管堆上分配新对象.
分配新对象 只会在以下两种情况:
- 动态构造字符串,其长度超过了设置的容量.
- 调用StringBuilder的ToString方法.
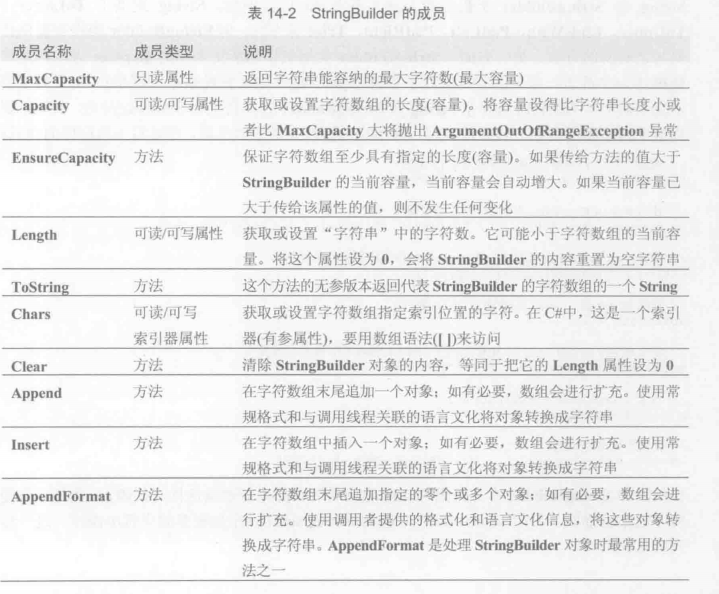

// 有参属性,索引器
// IL代码 StringBuilder::get_Chars(int32)
[IndexerName("Chars")] // 不加这个,默认是 get_Item
public char this[int index]
// 用法如同使用数组
StringBuilder sb = new StringBuilder("1234567");
Console.WriteLine(sb[1]);
Length属性设为0等同于内容重置为空字符串, 还等同于Clear方法.Append在字符数组 后追加 一个对象,有必要会进行扩充.Insert在字符数组 中插入 一个对象,有必要会进行扩充.AppendFormat在字符数组末尾追加0个或多个对象.AppendLine追加一行中止符或者一个带有中止符的字符串.
’\0’字符在C#中意味着字符串结束, 后面的字符不显示.
string.Replace('\0','*')
Equals两个StringBuilder对象具有相同最大容量,字符数组容量和字符内存才返回true.
大多数方法返回的都是对同一个StringBuilder对象的引用.
String类提供的一些方法,StringBuilder类并没有提供对应的方法.
- ToLower
- ToUpper
- EndsWith
- PadLeft
- PadRight
- Trim
StringBuilder提供了更全面的Replace方法,允许替换一部分字符串而不是整个.
// 因为StringBuilder提供转换大写的方法,需要用String的方法来中转一下
StringBuilder sb = new StringBuilder();
sb.AppendFormat("Jeffrey Richter").Replace(" ", "-");
// 推荐使用忽视语言文化的转换
// 将StringBuilder转成string以便将所有字符串转换成大写
String s = sb.ToString().ToUpperInvariant();
// 清空StringBuilder,分配新的char数组
sb.Length = 0;
// 将全部大写的String加载到StringBuilder中执行其他操作
sb.Append(s).Insert(8, "Marc-");
// 再转回String ,向用户显式
s = sb.ToString();
// 输出: JEFFREY-Marc-RICHTER
Console.WriteLine(s);
因为StringBuilder提供转换大写的方法,需要用String的方法来中转一下.
