属性
CLR支持两种属性:
- 无参属性
- 索引器
无参属性
属性是用来干嘛的?解决了什么问题?
- 面向数对象设计重要原则之一,数据封装. 意味着类型的字段永远不应该公开.否则很容易因为不恰当的使用而破坏对象的状态.
- 例如
e.Age = -1; //年龄不可能为负数;
- 例如
- 设置为私有字段private后,要修改字段添加
访问器(accessor)方法,这样就要编写额外的方法 - 调用方法不能直接引用字段名,需要调用方法名
- 例如
e.SetAge(2);
- 例如
为了解决以上问题,C#提供了属性property机制.
private string name;
private int age;
public string Name
{
get { return name; }
set { name = value; }
}
public int Age
{
get { return age; }
set
{
if (age < 0 && age > 200)
throw new ArgumentOutOfRangeException("age不在正常范围", value.ToString());
age = value;
}
}
/// 调用时,可以直接引用字段名
e.Name = "aaaa";
属性的用法
- 支持静态,实例,抽象,虚属性.
- 可以用任意
可访问性来修饰get/set. - 属性不能重载,即不能定义名称相同,类型不同的属性.
只读属性: 只写get标识;只写属性:只写set标识- set方法中包含隐藏参数叫做
value,表示赋给属性的值。
私有字段 通常被称为支持字段.
自动实现的属性(AIP)
如果只为一个私有字段而创建属性,C#提供了更简洁的语法.称为AIP(Automatiocally Implemented Property).
// 声明属性不需要提供get/set的实现, C#会自动声明一个私有字段
public string Name{set;get;}
自动实现的属性(AIP)不建议使用的理由:
- 没有简单的语法初始化AIP,要在构造器中显式初始化每个AIP
- AIP的私有字段名称有编译器决定,每次重新编译都可能会更改这个名称.因此,任何类型只要含有AIP就没办法对该类型进行反序列化. 所以在想要序列化的类中不要使用AIP功能.
- 调用时不能再get/set上设置断点.手动实现属性方法可以设置.
- AIP属性必然是可读可写的.
- get或set方法,如果要显式实现,那么两个方法都要显式实现,不能一个自动一个显式.
属性字段差别列表
- 属性索引器不得作为out或ref参数传递,字段可以.
- 属性看起来和字段相似,但是本质上是方法.
- 属性方法可能抛出异常;字段访问永远不会.
- 线程同步不要使用属性,要使用方法. 属性方法可能花较长时间执行,字段访问总是立即完成.
- 属性可以只读或者只写, 字段访问总是可读或可写(一个例外是readonly字段仅在构造器中可写).
属性的唯一好处是提供了简化的语法.
对象和集合初始化器
构造对象并设置对象的一些公共属性,为了简化这个常见的编程模式,使用下面这个语法:
Employee e = new Employee(){ Name = "Jeff", Age = 45 };
等同于
Employee e = new Employee();
e.Name = "Jeff";
e.Age = 45;
允许组合多个函数,增强了可读性.(函数的组合使用:扩展方法)
Employee e = new Employee(){ Name = "Jeff", Age = 45 }.ToString.ToUpper();
要用无参构造函数,可以省略大括号前的圆括号,
new Employee { Name = "Jeff", Age = 45 }
如果类型的属性实现了IEnumerable或IEnumerable
集合的初始化是一种相加(additive)操作,而不是替换(replacement)操作.
- 编译器会假定属性类型提供了Add方法,然后生成代码来
调用Add方法. - 如果属性类型
未提供Add方法,则不允许使用集合初始化语法.
class Program
{
static void Main(string[] args)
{
MyClass mc = new MyClass()
{
MStudent =
{
"A",
"B",
"C"
}
};
foreach (var student in mc.MStudent)
{
Console.WriteLine(student);
}
}
}
public sealed class MyClass
{
// 私有字段
private List<String> m_Student = new List<string>();
// 只读属性
public List<string> MStudent
{
// C#7 方法体表达式
// constructors, finalizers, get, set
// get只读
get => m_Student;
}
public MyClass() { }
}
匿名类型
利用C#的匿名类功能,可以用很简洁的语法来自动声明不可变的元组类型.
元组类型:是含有一组属性的类型.
// 没有在new后指定类型名称,编译器会自动创建类型名称
// 因为不知道类型名称,也就不知道o1声明的是什么类型
// 可以像var
var o1 = new { Name = "aa", Year = 1989};
// Nameaa,Year1989.
Console.WriteLine("Name{0},Year{1}.",o1.Name,o1.Year);
String Name = "B";
DateTime dt = DateTime.Now;
// 还可以这么写
var o2 = new { Name, dt.Year };
- 编译器会推断每个
表达式的类型. - 创建推断类型的
私有字段. - 为每个字段创建
公共只读属性. - 创建一个
构造器来接受所有这些表达式.- 在构造器代码中, 会用传给它的
表达式的求值结果来初始化私有只读字段.
- 在构造器代码中, 会用传给它的
- 编译器还会重写Object的Equals,GetHashCode和ToString方法.
- 任何字段不匹配就返回false,否则true.
- 返回根据每个字段的哈希码生成的一个哈希码.
- 返回”属性名=值”对的以逗号分隔的列表.
- 匿名类的属性是只读的. 防止对象的哈希码发生改变.如果以哈希码为键,更改了哈希码,这就造成再也找不到它.
编译器在定义匿名类型时, 如果定义了多个匿名类型,而且这些类型具有相同的结构,那么它只会创建一个匿名类型定义.
匿名类经常与LINQ(语言集成查询)配合使用
可以用LINQ执行查询,从而生成由一组对象构成的集合. 这些对象都是相同的匿名类型.
- 匿名类型不能泄露到方法外部.
- 方法也不能返回对匿名类的引用,
- 虽然可以将匿名类视为Object,但是没法将Object类的变量转型回匿名类.因为不知道匿名类在编译时的名称.
Tuple类型
和匿名类型相似,
Tuple创建好之后就不可变了,所有属性只读.- 提供了CompareTo,Equals,GetHashCode和ToString方法,以及Size属性,
- 可以比较两个Tuple对象,对他们的字段进行比对.
class CLRTuple
{
private static Tuple<int, int> MinMax(int a, int b) {
return new Tuple<int, int>(Math.Min(a, b), Math.Max(a, b));
}
private static void TupleTypes()
{
var minmax = MinMax(6, 2);
// Tuple类型,属性一律被称为Item#,无法进行改变
// 应该在自己的代码中添加详细的注释,说明每个Item#代表着是什么
Console.WriteLine("Min{0}Max{1}", minmax.Item1, minmax.Item2);
}
}
// 当需要创建多于8个元素的一个Tuple时,可以将Rest参数传递到下一个Tuple如下
var t=Tuple.Create(0,1,2,3,4,5,6,Tuple.Create(7,8));
Console.WriteLine("{0}{1}{2}{3}{4}{5}{6}{7}{8}",
t.Item1, t.Item2, t.Item3, t.Item4, t.Item5, t.Item6, t.Item7,
t.Rest.Item1.Item1, t.Rest.Item1.Item2);
)
除了匿名类型和Tuple类型,ExpandoObject类和dynamic配合使用
可以用另一种方式将一系列属性(键值对)组合到一起.

有参属性(索引器)
可以看成是对[]操作符的重载.
属性的get访问器方法 不接受参数,所以称为 无参属性.
C#称有参属性为 索引器.
get访问器:接受一个或多个参数.set访问器:接受两个或多个参数.
索引器使得对象可按照与数组相似的方法进行索引。
CLR是以相同方式对待有参属性和无参属性.
static void Main(string[] args)
{
TestIndex<String> str= new TestIndex<string>();
// 定义了索引器之后可以像数组的方式一样访问类
str[0] = "A";
str[2] = "B";
}
class TestIndex<T>
{
T[] arr = new T[100];
// 定义[]索引器
public T this[int i]
{
get { return arr[i]; }
set { arr[i] = value; }
}
}
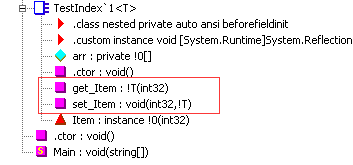
提示:查看文档,留意类型是否提供了名为Item的属性,从而判断该类型是否提供了索引器.
例如System.Collections.Generic.List类型提供了名为Item的公共实例属性,它就是List的索引器.
如果会有其他语言的代码访问索引器,可能需要更改get/set方法名称
C#编程中永远看不到 Item这个名称,所以一般不需要关心这个.
class TestIndex<T>
{
T[] arr = new T[100];
// 定义[]索引器
[IndexerName("Method")]
public T this[int i]
{
get { return arr[i]; }
set { arr[i] = value; }
}
}

System.String类型是改变了索引器名称的一个例子.String的索引器名称是Chars,而不是Item. 这个只读属性允许从字符串中获得一个单独的字符,对于不用[]操作符语法来访问这个属性的编程语言,Chars是更有意义的名称.
索引器注意事项
- C#用
this[...]作为索引器的语法.- 索引器语法不允许开发人员指定名称,编译器默认生成get_Item和set_Item方法名.
- Item方法名可以用
[IndexerName("..")]特性修改
- 只允许在对象的实例上定义索引器.
- 不支持静态索引器属性.
- 索引器可以被重载.一个类可以有多个索引器,只要参数集不同即可.
- 索引器可以多个参数,可以像二维数组.
class TestIndex<T>
{
T[] arr = new T[100];
T[,] arr1 = new T[10,10];
// 定义索引器
public T this[int i]
{
get { return arr[i]; }
set { arr[i] = value; }
}
// 定义两个形参的索引器
public T this[int i,int j]
{
get { return arr1[i,j]; }
set { arr1[i,j] = value; }
}
}
- 对于CLR来说有参和无参属性是无区别的,可以用相同的
System.Reflection.PropertyInfo类来发现有参属性和它的访问器方法之间的关联.
调用访问器方法时的性能
对于简单的get/set方法 ,JIT编译器会将代码内联(嵌入到调用它的方法中去),这样使用属性就没有性能上的损失,避免了在运行时发出调用所产生的开销,会使编译好的方法变得更大.
由于属性访问器包含的代码很少,所以内联所生成的本机代码很小,执行的也会更快.
- JIT编译器在 调试代码时不会内联属性方法. 内联代码会难以调试.
- 发行版本中,访问属性时的性能可能比较快.
- 字段访问在调试和发布版中,速度都很快.
属性访问器的可访问性
如果2个访问器需要不同的可访问性,
- C#要求必须为属性本身指定限制最小的(比访问器访问性限制小),
- 两个访问器只能选择一个访问器来使用限制较大的.(不能两个都用)
// 限制最小的可访问性public
public String Name
{
get{ return m_name; }
// 限制较大的protected(相对于Public)
protected set { m_name = value; }
}
// 例子二
protected string A
{
// private get => a; // 会报错
get => a;
private set => a = value;
}
泛型属性访问器方法
C#不允许属性引入它自己的泛型类型参数. 属性不应该和行为沾边,公开对象的行为,无论是不是泛型都应该定义方法,而不是用属性.
