回顾总结
2019年8月22日
值类型一般在线程栈上分配
- 值类型不受垃圾回收器控制
- 随着变量生命周期结束而被栈释放
- 所有值类型都是隐式密封的
- 值类型称为结构或枚举.
System.ValueType的后代不全是值类型,System.Enum就是唯一的特例.- 它直接继承自System.ValueType,
System.Enum和System.ValueType本身是引用类型。
new操作符,编译器会判断类型是值类型和引用类型
- 会生成正确的IL代码分配在线程栈 或者 堆中.
值类型对象有 未装箱和已装箱两种形式. 引用类型总是处于已装箱形式.
值类型如果不与非托管代码互操作,就应该覆盖C#编译器的默认设定改为[StructLayout(LayoutKind.Auto)]
- 不覆盖默认是LayoutKind.Sequential
拆箱就是获取指针的过程
- 拆箱不要求在内存中复制任何字节,指针指向的是已装箱实例中的未装箱部分
- 然后进行一次字段复制到线程栈过程.
- 已装箱对象在拆箱过程时,如果引用对象不是所需的值类型,会抛InvalidCastException
- 先拆箱为正确类型,再转型,
Int16 y = (Int16)(Int32)o;// o里存放的是Object->Int32的已装箱对象
ToString方法 代替 直接使用值类型传递给object参数的方法, 可以减少一个装箱操作.
- 例如:Console.WriteLine编辑器选择Concat的重载版本去实现3个参数的合并
Concat(object,object,object)- 不建议使用
Console.WriteLine(v + "," + o );建议使用Console.WriteLine(v.ToString() + "," + (Int32) o );减少装箱操作.
大多数方法重载的目的是减少常用的值类型装箱次数.
- 可以将方法定义为泛型,通过约束限制为值类型,这样获取任何值类型而不必装箱.
- 如果要对一个值类型反复装箱, 建议手动写代码装箱
Object o = v;减少装箱次数
2019年9月25日
值类型里包含引用类型,如:
struct包含class对象。- 该引用类型将作为值类型的成员变量,堆栈上将保存该成员的引用,而成员的实际数据还是保存在托管堆中.
引用类型包含值类型,如:
class包含int。- 如果是
成员变量,做为引用类型的一部分将分配在托管堆上。如果是方法里的局部变量,则分配在该段代码的线程栈上。
- 如果是
引用类型和值类型
CLR支持两种类型: 引用类型和值类型.
引用类型总是从托管堆分配. C#的new操作符返回对象内存地址—-指向对象数据的内存地址.
使用引用类型必须留意性能问题.
- 内存必须从托管堆分配.
- 堆上分配的每个对象都有一些额外成员,这些额外成员必须初始化.
- 对象中的其他字节(为字段设置的字节)总是设为0.
- 从对管堆分配对象时,可能强制执行一次垃圾回收.
为了提高性能,CLR提供了名为”值类型”的轻量级类型.
值类型 的实例一般在线程栈上分配.
- 可以作为字段嵌入引用类型的对象中
- 在代表值类型实例的变量中 不包含指向实例的指针.
- 实例中包含了实例本身的字段(值). 所以操作实例中的字段(值)不需要提领指针.
- 值类型不受垃圾回收器的控制.
- 所有值类型都是隐式密封,防止用作其他应用类型或值类型的基类.
值类型缓解了使用托管堆的压力,并减少了应用程序生存期内的垃圾回收次数.
在非托管环境(C/C++)中声明类型后, 使用该类型的代码会决定是在线程栈上还是应用程序的堆中分配该类型的实例.
托管代码中,要由定义类型的开发人员决定在什么地方分配类型实例,使用此类型的人对此没有控制权.
查看文档区分引用类型和值类型
- 在文档中查看类型时, 任何称为 类 的类型都是引用类型. 例如System.Exception类…
- 所有值类型都称为 结构 或 枚举. 例如:System.Int32结构…
结构&枚举
所有结构都是抽象类型System.ValueType的直接派生类.System.ValueType本身又直接从System.Object派生.
- 根据定义, 所有值类型都必须从
System.ValueType派生. - 所有枚举都从
System.Enum抽象类型派生,System.Enum从System.ValueType派生.
CLR和所有编程语言都会给予枚举特殊待遇(直接支持各种强大的操作,非托管环境中就不这样了.)
引用类型和值类型的区别
// 引用类型,因为class
class SomeRef { public Int32 x; }
// 值类型
struct SomeVal{ public Int32 x; }
static void ValueTypeDemo()
{
// 图示左边部分
SomeRef r1 = new SomeRef(); // 在堆上分配
// 使用new看似是要在托管堆上分配实例,实际是C#编译器知道SomeVal是值类型
// 所以会正确的生成IL代码,在线程栈上分配,
// C#还会确保值类型中的所有字段都初始化为零.
// SomeVal v1; 还可以这么写. 但是C#认为此处v1没有初始化.
// 如果直接使用Int32 a = v1.x;将不能通过编译
SomeVal v1 = new SomeVal(); // 在栈上分配. 使用new操作符,C#会认为已经初始化.
r1.x = 5; // 提领指针
v1.x = 5; // 在栈上修改
// 图示右边部分
SomeRef r2 = r1; // 只复制引用(指针)
SomeVal v2 = v1; // 在栈上分配并复制成员
r1.x = 8; // r1.x和r2.x都会更改
v1.x = 9; // v1.x会更改,v2.x不变,为5
}
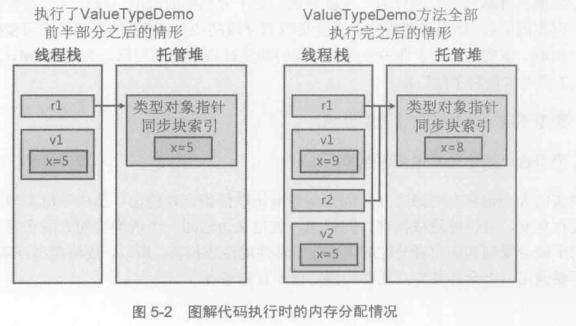
在代码中使用类型时, 必须注意是引用类型还是值类型,这会极大的影响在代码中表达自己意图的方式.
设计类型时,满足什么条件才声明为值类型?
- 类型具有基元类型的行为. 是十分简单的类型,没有成员会修改类型的任何实例字段.
- 如果类型没有提供会更改字段的成员,就说该类型不可变(immutable).
- 类型不需要从其他任何类继承.
- 类型也不派生出其他任何类型
类型实例大小也应该在考虑范围内,因为实参默认以值方式传递,造成对值类型实例中的字段进行复制,影响性能.
- 类型的实例较小(16字节或更小)
- 类型的实例较大(大于16字节),但不作为方法实参传递,也不从方法返回
值类型的主要优势以及自身的局限
值类型主要的优势是不作为对象在托管堆上分配.值类型对象有两种表示形式:未装箱和已装箱. 引用类型总是处于已装箱形式.值类型从System.ValueType派生. 该类型提供了与System.Object相同的方法,但重写了Equals方法,能在两个对象的字段值完全匹配的前提下返回true.还重写了GetHashCode方法.会将字段中的值都考虑在内.但是这个实现存在性能问题.所以定义自己的值类型时应该重写Equals和GetHashCode方法,并提供显式实现.- 由于不能将
值类型作为基类或新的引用类型,所以不应当在值类型中引入任何新的虚方法,所有方法不能是抽象的,并且隐式密封不可重写. 引用类型的变量包含堆中对象的地址.引用类型的变量创建时默认初始化为null(表示当前不指向任何有效对象). 试图使用null引用时会报NullReferenceException异常.值类型的变量总是包含其基础类型的一个值.而值类型的初始化都为0. 值类型变量不是指针,不会报NullReferenceException异常.CLR允许为值类型添加可空标识.- 将
值类型变量赋给另一个值类型变量,会执行逐字段复制.引用类型的变量赋给另一个引用类型的变量值只复制内存地址. - 两个或多个
引用类型变量能引用堆中的同一对象,所以对一个变量操作可能会影响到另一个变量引用的对象.值类型则不会影响另一个值类型变量. - 由于
未装箱的值类型不在堆上分配, 定义了该类型的实例的方法不再活动(变量的生命周期结束),为它们分配的栈存储就会被释放.
CLR如何控制类型中的字段布局?
为了提高性能,CLR能按照它所选择的任何方式排列类型的字段. 例如:CLR可以在内存中重新安排字段的顺序,将对象引用分为一组,同时正确排列和填充数据字段.
定义类型时,针对类型的各个字段,你可以告诉CLR按照指定的顺序排列,还是按照CLR自己认为合适的方式重新排列.
如何告诉CLR怎么排列?
- 要为自己定义的类或结构应用
System.Runtime.InteropServices.StructLayoutAttribute特性.- 向该特性的构造器传递
LayoutKind.Auto: 让CLR自动排列字段. - 顺序布局:传递
LayoutKind.Sequential: 让CLR保持你的字段布局. - 精确布局:传递
LayoutKind.Explicit: 指定每个字段的偏移量,利用偏移量在内存中显示排列字段.
- 向该特性的构造器传递
- 如果不指定
StructLayoutAttribute,则CLR按照自己的方式. - 注意:C#编译器有默认设定:
- 默认
引用类型选择LayoutKind.Auto - 默认
值类型选择LayoutKind.Sequential - 这是因为C#编译器团队认为和
非托管代码互操作时会经常用到结构.为此,字段必须保持程序员定义的顺序. - 假如创建的值类型不与
非托管代码互操作,就应该覆盖C#编译器的默认设定.
- 默认
using System;
using System.Runtime.InteropServices;
// 让CLR自动排列字段以增强这个值类型的性能
// 覆盖掉C#编译器默认的`LayoutKind.Sequential`设置
[StructLayout(LayoutKind.Auto)]
internal struct SomeValType
{
private readonly Byte m_b;
....
}
LayoutKind.Explicit说明
构造器传递了LayoutKind.Explicit之后, 要向值类型中的每个字段都应用System.Runtime.InteropServices.FieldOffsetAttribute特性的实例.并且向该特性传递Int32值来指出字段第一个字节距离实例起始处的偏移量(以字节为单位).
显示布局常用来模拟非托管C/C++中的union,因为多个字段可起始于内存的相同偏移位置.
注意在类型中:一个引用类型和一个值类型互相重叠是不合法的.多个值类型相互重叠则是合法的.为了是这样的类型能够验证,所有重叠字节都必须能通过公共字段访问.
union是特殊类,union中的数据成员在内存中的存储是相互重叠.每个数据成员都从相同的内存地址开始.
分配给union的存储区数量是包含它最大数据成员所需的内存数, 同一时刻只有一个成员可以被赋值.
(1)同一个内存段可以用来存放几种不同类型的成员,但在每一个时刻只能存在其中一种,而不能同时存放几种,即每一瞬间只有一个成员起作用,其它的成员不起作用,不能同时都存在和起作用;
(2)共用体变量中起作用的成员是最后一个存放的成员,在存入一个新的成员后,原有的成员就会失去作用,即所有的数据成员具有相同的起始地址。
(3)union和struct都是由多个不同的数据成员组成,但是union所有成员共享一段内存地址,只存放最后一次赋值的成员值,而struct可以存放所以有成员的值。
(4)union的大小是所有成员中所占内存最大的成员的大小,struct是所有成员的大小的“和”。
using System;
using System.Runtime.InteropServices;
// 让开发人员显示排列这个值类型的字段
[StructLayout(LayoutKind.Explicit)]
internal struct SomeValType
{
[FieldOffset(0)]
private readonly Byte m_b;// m_b和m_x字段在该类型的实例中相互重叠
[FieldOffset(0)]
private readonly Int16 m_x; // m_b和m_x字段在该类型的实例中相互重叠
}
值类型的装箱和拆箱
值类型不作为对象在托管堆中分配,不被垃圾回收,也不通过指针进行引用.
using System;
using System.Collections;
namespace ConsoleApp1
{
struct Point{public Int32 x, y;}
class Program
{
static void Main(string[] args)
{
ArrayList a = new ArrayList();
Point p; // 分配一个Point,不在堆中分配
// 每次迭代都初始化一个`Point值类型字段`, 并将该Point存储到ArrayList中.
for (int i = 0; i < 10; i++)
{
p.x = p.y = i; // 初始化值类型中的成员
a.Add(p); // 对值类型进行装箱,将引用添加到ArrayList中
}
}
}
}
ArrayList中究竟存储了什么? 是Point结构还是Point结构的地址?
想要知道答案需要研究ArrayList的Add方法.
Add方法原型:public virtual Int32 Add(object value);
- 参数是
object,也就是说Add获取对托管堆上的一个对象的引用(指针)来作为参数. - a.Add(p); 之前的代码传递的是Point,是值类型.
- 为了使代码正确工作,Point值类型必须转换成真正的,在堆中托管的对象,而且必须获取对该对象的引用
- 对
值类型转成引用类型要使用装箱机制.
装箱机制发生的事情
- 在托管
堆中分配内存. 分配的内存是值类型各字段所需的内存量(还要加上托管堆所有对象都有的两个额外成员:类型对象指针和同步块索引所需的内存量). - 值类型的字段复制到新分配的堆内存.
- 返回对象地址, 现在该地址是对象引用:值类型成了引用类型.
在托管堆中分配相应的内存.
C#编译器自动生成对值类型实例进行装箱所需的IL代码. 但是仍需要理解内部的工作机制才能体会到代码的大小和性能问题.
在运行时,当前存在于Point值类型实例p中的字段复制到新分配的Point对象中. 已装箱Point对象(现在是引用类型)的地址传给Add方法. Point对象一直存在于堆中,直至被垃圾回收.
FCL现在包含一组新的泛型集合类, 非泛型集合类已经是过时的东西.
例如:应该使用System.Collections.Generic.List<T>类而不是System.Collections.ArrayList类.泛型集合类对非泛型集合类进行了大量改进.
- API得到简化和增强,性能也得到显著提升
- 允许开发人员在操作
值类型的集合时不需要对集合中的项进行装箱/拆箱- 开发人员还获得编译时的类型安全性, 减少强制类型转换次数.
拆箱机制
要从上面代码中的ArrayList a取第一个元素.
Point p = (Point)a[0];
- 它获取ArrayList的元素0包含的引用(指针), 试图放到
Point值类型的实例p中. - 为此,
已装箱Point对象中的所有字段都必须复制到值类型变量p中. 后者在线程栈上. - CLR分两步完成复制
- 第一步: 获取
已装箱Point对象的各个Point字段的地址. ← 此过程称为拆箱. - 第二步: 将字段包含的值从
堆复制到栈的值类型实例中.
- 第一步: 获取
拆箱不是直接将装箱过程倒过来, 装箱的代价被拆箱高得多.
- 拆箱就是获取指针的过程.
- 拆箱不要求在内存中复制任何字节. 指针指向的是已装箱实例中的未装箱部分.
- 拆箱操作后紧接着一次字段复制.
已装箱值类型在拆箱时的过程
- 如果包含”对已装箱值类型实例的引用”的变量为null,抛出NullReferenceException.
Point p = (Point)a[0];// a为null时
- 如果引用的对象不是所需值类型的已装箱实例,抛出InvalidCastException.
public static void Main()
{
Int32 x = 5;
object o = x; // 对x装箱,o引用已装箱对象
// 在对对象进行拆箱时,只能转型为最初未装箱的值类型(本例是Int32)
// 所以以下写法会抛出异常
Int16 y = (Int16)o; // 抛出InvalidCastException.
// 正确写法
Int16 y = (Int16)(Int32)o; // 先拆箱为正确类型,再转型
}
拆箱和复制例子
public static void Main()
{
Point p;
p.x = p.y = 1;
Object o = p; // 对p装箱; o引用已装箱实例
// 将Point的x字段变成2
p = (Point)o; // 对o拆箱, 将字段从已装箱的实例复制到[栈]变量中 (复制所有字段)
p.x = 2; // 更新[栈]变量的状态
o = p; // 对p装箱;o引用新的已装箱实例 (复制所有字段)
}
首先进行一次拆箱,再执行一次字段复制(到栈变量中),最后再执行一次装箱(在托管堆上创建全新的已装箱实例).
这个过程对应用程序性能影响较大.
此段代码用C++/CLI来写,效率会高很多,因为它允许在不复制字段的前提下,对已装箱的值类型进行拆箱,拆箱返回的是已装箱对象中的未装箱部分的地址(忽略对象的类型对象指针和同步索引块这两个额外成员),接着可以用这个指针来操作未装箱实例的字段(这些字段恰好在堆上的已装箱对象中).
C++/CLI直接在已装箱Point实例中修改Point的x字段的值. 就这避免了在堆上分配新对象和复制字段两次.
从IL代码查看编译器隐式生成的装箱代码
如果关心特定算法的性能,可以用ILDasm.exe这样的工具查看方法的IL代码,观察IL指令box都在哪些地方出现.
例子一
// 以下代码发生了3次装箱
public static void Main()
{
Int32 v = 5; // 值类型变量
object o = v; // 一次装箱
v = 123; // 将未装箱的值修改为123
Console.WriteLine(v + "," + (Int32) o );// 显示123,5
}
解析:
- 首先在栈上创建一个Int32未装箱值类型实例
v, 将其初始化为5. - 创建Object类型的变量
o, 让它指向v.- 因为
引用类型的变量始终是指向堆中的对象,所以C#生成正确的IL代码对v进行装箱,(复制所有字段到堆中) - 让
v的已装箱拷贝的地址存储到o中.
- 因为
- 接着,值123被放到
未装箱值类型实例v中, 但这个操作不会影响已装箱的Int32,后者值依然是5. - 接着调用WriteLine方法, 由于方法需要string对象作为参数,编辑器选择Concat的重载版本去实现3个参数的合并
Concat(object,object,object)- 第一个参数传递v(未装箱的值参数),需要进行装箱操作
- 第二个参数”,”,作为string对象,引用传递.
- 第三个参数,
(Int32) o, 先进行拆箱(但不紧接着执行复制),获取到在已装箱Int32中的未装箱Int32的地址.这个未装箱的Int32实例必须再次装箱. 将实例的内存地址传给arg2参数
- Concat方法调用每个对象的ToString方法,将每个对象的字符串连接起来.返给给WriteLine方法以最终显示.
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// 代码大小 47 (0x2f)
.maxstack 3
.locals init (int32 V_0,
object V_1)
IL_0000: nop // nop:没有什么意义;
// Int32 v = 5;
IL_0001: ldc.i4.5 // Ldc.I4 将所提供的 int32 类型的值作为 int32 推送到计算堆栈上。
IL_0002: stloc.0 //从计算堆栈的顶部弹出当前值并将其存储到索引 0 处的局部变量列表中。
// object o = v;
// 局部变量object o,位置设定为索引0
IL_0003: ldloc.0 //将索引 0 处的局部变量加载到计算堆栈上。
IL_0004: box [System.Runtime]System.Int32 // 将值类转换为对象引用(O 类型)。
IL_0009: stloc.1 //从计算堆栈的顶部弹出当前值并将其存储到索引 1 处的局部变量列表中。
// v = 123;
IL_000a: ldc.i4.s 123 // 将提供的 int8 值作为 int32 推送到计算堆栈上(短格式)。
IL_000c: stloc.0
// Console.WriteLine(v + "," + (Int32) o );
// 在WriteLine方法参数(object引用类型)中, 会对值类型的v产生装箱操作
IL_000d: ldloc.0
IL_000e: box [System.Runtime]System.Int32
IL_0013: ldstr "," // 推送对元数据中存储的字符串的新对象引用。
// Console.WriteLine(v + "," + (Int32) o );
// (Int32) o 拆箱操作,拆成原始的Int32值类型.
IL_0018: ldloc.1
IL_0019: unbox.any [System.Runtime]System.Int32
// 由于被作为WriteLine方法参数(object引用类型), 再进行装箱操作
IL_001e: box [System.Runtime]System.Int32
// 调用string的Concat方法连接字符串
IL_0023: call string [System.Runtime]System.String::Concat(object,object,object)
// 将Concat返回的string 传给WriteLine方法
IL_0028: call void [System.Console]System.Console::WriteLine(string)
IL_002d: nop
// 从Main返回,终止应用程序
IL_002e: ret
} // end of method Program::Main
如果改进一下,如下:
// 此处如果修改成如下代码,效率更高,避免了2次操作:一次装箱一次拆箱
Console.WriteLine(v + "," + o );// 显示123,5
对比一下IL代码
- 比之前版本小了10个字节. 第一个版本
额外的拆箱/装箱显然会产生更多的代码. 额外的装箱操作步骤会从托管堆中分配一个额外的对象, 将来对其进行垃圾回收.
.method private hidebysig static void Main(string[] args) cil managed
{
.entrypoint
// 代码大小 37 (0x25)
.maxstack 3
.locals init (int32 V_0,
object V_1)
IL_0000: nop
IL_0001: ldc.i4.5
IL_0002: stloc.0
IL_0003: ldloc.0
IL_0004: box [System.Runtime]System.Int32
IL_0009: stloc.1
IL_000a: ldc.i4.s 123
IL_000c: stloc.0
IL_000d: ldloc.0
IL_000e: box [System.Runtime]System.Int32
IL_0013: ldstr ","
IL_0018: ldloc.1
IL_0019: call string [System.Runtime]System.String::Concat(object,object,object)
IL_001e: call void [System.Console]System.Console::WriteLine(string)
IL_0023: nop
IL_0024: ret
} // end of method Program::Main
进一步提升代码的性能:
v.ToString(),返回是的String,是引用类型,不需要装箱,减少一个装箱操作.
Console.WriteLine(v.ToString() + "," + (Int32) o );
对应的IL代码则是: IL_000f: call instance string [System.Runtime]System.Int32::ToString()
例子二
// 以下代码只发生了一次装箱.
static void Main(string[] args)
{
Int32 v = 5;
// 装箱
Object o = v;
// 修改栈, 不影响已装箱的o
v = 123;
// public static void WriteLine(int value)
// 方法WriteLine是传值的方式,不需要装箱
Console.WriteLine(v); // 123
// 拆箱
v = (Int32) o;
Console.WriteLine(v); // 5
}
FCL重载了很多常用值类型的方法,减少常用值类型的装箱次数
public static void WriteLine(double value);
public static void WriteLine(float value);
public static void WriteLine(int value);
...
大多数方法进行重载唯一的目的就是减少常用值类型的装箱次数.
但是FCL不可能接受你自己定义的值类型. 也可能FCL没有提供对应的重载版本,那调用方法传递值类型参数时,就是调用Object参数的重载版本. 将值类型实例作为Object传递会造成装箱.
定义自己的类时, 可将类中的方法定义为泛型(通过泛型约束将类型参数限制为值类型), 这样方法就可以获取任何值类型而不必装箱.
例子三(如果要反复对一个值类型装箱,请改为手动方式)
static void Main(string[] args)
{
Int32 v = 5;
// v会被装箱3次,浪费时间和内存
Console.WriteLine($"{v}+{v}+{v}");
// 对v手动装箱一次
Object o = v;
// 编译下一行不会发生装箱行为
// 内存利用还是执行速度都比上一段代码更胜一筹
Console.WriteLine($"{o}+{o}+{o}");
}
附加一个主题: C#值类型与引用类型相互嵌套
- 值类型里包含引用类型,如:
struct包含class对象。
该引用类型将作为值类型的成员变量,堆栈上将保存该成员的引用,而成员的实际数据还是保存在托管堆中.
- 引用类型包含值类型,如:
class包含int。
如果是成员变量,做为引用类型的一部分将分配在托管堆上。如果是方法里的局部变量,则分配在该段代码的线程栈上。
public class ReceiveTest : MonoBehaviour
{
private void Awake()
{
//对于引用类型new才会有新的内存存在,不new而赋值不会有新的内存存在。
//对于值类型在使用“=”赋值时,会自动调用隐式的构造函数,会new一次。
FruitStruct tf = new FruitStruct(100);
FruitStruct tf2 = tf;
tf2.fruit.apple = 200;
tf2.num = 200;
print(tf.fruit.apple);//打印200 说明共用托管堆中同一个FruitClass类实例
print(tf.num);//打印100 说明堆栈上存在各自的num
}
}
public class FruitClass
{
public int apple;
}
public struct FruitStruct
{
public int num;
public FruitClass fruit;
public FruitStruct(int num)
{
this.num = num;
fruit = new FruitClass();
fruit.apple = num;
}
}
