回顾总结
2019年8月22日
允许转换安全的隐式转换.
- 转换安全: 不发生数据丢失的情况.比如从
Int32转换为Int64. - 隐式转换: 不用写 (类型) 的方式
- 显示转型: 用()注明类型
- 转换安全: 不发生数据丢失的情况.比如从
丢失精度时, 会向下取整.
- 在转型时,
float6.8 放入int中会截断小数点后的数,放入6
- 在转型时,
字面值会在编译期就完成表达式求值.
String s = "a " + "bc";// 生成的代码将s设为"a bc"
算术运算符溢出处理
- checked / unchecked
- 将有溢出风险的计算语句放入块中, 如果块中调用方法不会有任何作用.
- 捕捉
OverflowException异常
Decimal是特殊的基元类型,CLR不会为此生成特殊的指令
- 编译器会生成代码来调用Decimal的成员方法,处理速度慢于其他基元类型
- 溢出检查操作符无效
BigInteger
UInt32数组来表示任意大的整数- 没有上限和下限
- 不会抛
OverflowException可能会抛OutOfMemoryException
编程语言的基元类型
什么是基元类型
编译器直接支持的数据类型称为基元类型(primitive type).
基元类型直接映射到Framework类库FCL中存在的类型.例如C#中的int直接映射到的System.Int32类型.
MSDN文档将primitive type翻译成”基元类型”,而不是容易混淆的”基本类型”.
以下四行代码都能正确编译,并能生成完全相同的IL代码.
// 最方便的语法
int a = 0;
// 方便的语法
System.Int32 a = 0;
// 不方便的语法
int a = new int();
// 最不方便的语法
System.Int32 a = new System.Int32();
// 从另外一个角度可以认为C#编译器自动假定所有源代码都添加了一下using指令(取别名作用)
using sbyte = System.SByte;
using byte = System.Byte;
using short = System.Int16;
using ushort = System.UInt16;
using int = System.Int32;
using uint = System.UInt32;
...
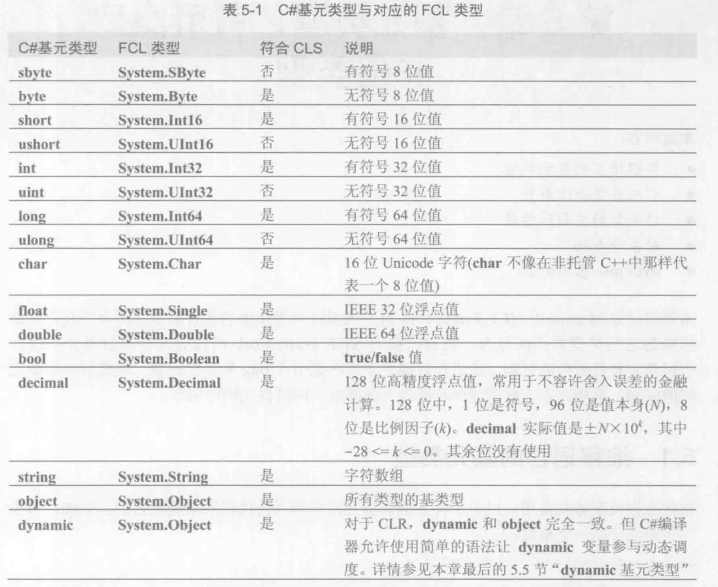
基元类型对应的FCL类型
是要是符合CLS公共语言规范的类型,其他语言都提供了类似的基元类型. 不符合的就不一定支持了.
关于关键字和完整的系统类型名称
C#语言规范:”从风格上说,最好使用关键字,而不是使用完整的系统类型名称.”
作者认为: 更好的是使用FCL类型名称,完全不用基元类型名称.
事实上,作者希望编译器根本不提供基元类型名称, 而是强迫开发人员使用FCL类型名称.理由如下:
- 有些程序员纠结用
string还是String. 由于C#的string(这是关键字)直接映射到System.String类型(这是FCL库中的类型). 所以两者没有区别.
误区: 有些开发人员说32位系统上int代表32位整数,64位系统上int代表64位整数,这个说法是错误的.
因为c#的int始终映射到System.Int32类型. 所以不管在什么操作系统上运行,代表的都是32位整数.
如果用Int32,这样的误解就没有了.
C#的
long类型映射到的是System.Int64,而其他编程语言中可能映射到Int16或Int32. 例如C++/CLI就将long视为Int32. 事实上大多数语言不将long当做关键字.根本不编译使用了它的代码.FCL的许多方法都将类型名作为方法名的一部分.例如BinaryReader类型的方法包括ReadBoolean,ReadInt32,ReadSingle等, 而System.Convert类型的方法包括ToBoolean,ToInt32,ToSingle等.
// 虽然语法上没问题, 但float的那一行无法一下子判断该行的正确性.
BinaryReader br = new BinaryReader(...);
// 使用float C#关键字
float val = br.ReadSingle(); // 正确,但感觉别扭
// 使用Single FCL类型名称
Single val = br.ReadSingle();// 正确,感觉自然
- 平时只用C#的许多程序员逐渐忘了还可以用其他语言写面向CLR的代码.
C#主义逐渐入侵类库代码.例如:FCL几乎完全是用C#写的,FCL团队向库中引入了Array的GetLongLength这样的方法,该方法返回的是Int64值.这种值在C#中确实是long,但是在其他语言比如C++/CLI中不是. 另一个例子是:System.Linq.Enumerable的LongCount方法.
考虑到以上原因,本书坚持使用FCL类型名称.
System.Int32 为什么能转 System.Int64?
在许多编程语言中,一下代码都能正确编译并运行:
Int32 i = 5;//32位值
Int64 i = i;//隐形转型为64位值
但是根据上一章内容,对类型转换的讨论,你或许认为上述代码无法编译. 毕竟System.Int32和System.Int64是不同的类型.互相不存在派生关系. 但是能正确编译上述代码,运行起来也没有问题.
原因是: C#编译器非常熟悉基元类型,会在编译代码时应用自己的特殊规则.
- 具体的说,C#编译器支持与
类型转换,字面值(直接量或文字常量)以及操作符有关的模式.
转型
编译器能执行基元类型之间的隐式或显示转型.
Int32 i = 5; //从Int32隐式转型为Int32
Int64 l = i; //从Int32隐式转型为Int64
Single s =i; //从Int32隐式转型为Single
Byte b = (Byte)i;// 从Int32显示转型为Byte
Int16 v = (Int16)s;//从Single显示转型为Int16
只有在转换安全的时候,C#才允许隐式转型.
什么是转换
安全的时候?- 是指不会发生数据丢失的情况. 比如从
Int32转换为Int64.
- 是指不会发生数据丢失的情况. 比如从
如果可能
不安全,C#就要求显示转型.- 对于数值类型,
不安全意味着转换后丢失精度或数量级. - 例如
Single(float IEEE32位浮点值),转换为Int16(short 有符号16位)也要求显示转型.因为Single能表示比Int16更大数量级的数字(会丢失精度).
- 对于数值类型,
C#编译器总是对转型结果进行截断
比如 6.8的Single(float IEEE32位浮点值)转型为Int32,
C#总是对结果进行截断(向下取整), 结果是将6放入Int32类型中.
有些编译器可能会将结果向上取整为7.
字面值
字面值可被看成是类型本身的实例.
// 实例 调用 实例方法
Console.WriteLine(123.ToString() + 456.ToString()); // 123456
// 如果表达式由字面值构成, 编译器在编译时就能完成表达式求值.从而增强应用程序性能.
Boolean found = false;// 生成的代码将found设为0
Int32 x = 100 + 20 + 3;// 生成的代码将x设为123
String s = "a " + "bc";// 生成的代码将s设为"a bc"
checked 和 unchecked 基元类型操作
对基元类型执行的许多算术运算符都可能造成溢出:
// byte 2^8 = 256
Byte b = 100;
// 100 +200 = 300
// 执行此处算术运算符时, 要求所有的操作数扩大到32位(64位,如果有操作数需要超过32位来表示的话)
// b 和 200 都不超过32位,则先转换成32位值,然后加到一起,结果是一个32位的十进制300.
// 然后该值存回b变量前**必须转型为Byte, C#不隐式执行此操作.**
b = (Byte)(b + 200); // b 现在为 44
溢出处理
- 溢出大多数时候是不希望出现的,会导致应用程序行为失常.但是极少数时候计算哈希值和校验和,这种溢出可以接受.
- 不同语言处理溢出的方式不同, C/C++不将溢出视为错误,允许值回滚.VB则视为错误,并抛出异常.
回滚:一个值超出允许的最大值时,回滚到一个非常小的,负的或者未定义的值.
CLR提供了一些特殊的IL指令. 允许程序员自己决定如何处理溢出. CLR有一个add指令,作用是将两个值相加,但不执行溢出检查,还有一个add.ovf指令,会在溢出时抛System.OverfolwException异常.
溢出检查默认是关闭的. 编译器生成IL代码时,将自动使用加减乘和转换指令的无溢出检查版本.代码能更快的运行./checked+编译器开关在生成代码时使用溢出检查版本.这样CLR会检查这些运算,判断是否发生溢出,并抛出异常.- 除了全局性的打开和关闭溢出检查, 程序员可以在代码的特定区域控制.
- unchecked 操作符
- checked 操作符
UInt32 invalid = unchecked( (UInt32) (-1)); // OK
Byte b = 100;
// 会抛出OverflowException异常
// 这个过程中,b和200会转成32位值,
// 300 转成 Byte就会抛出异常
b = checked((Byte)(b + 200));
// b包含44, 不会抛出异常.
b = (Byte)checked(b + 200);
C#还支持checked和unchecked语句. 可以是语句块中的代码都进行或不进行溢出检查.
checked和unchecked语句 唯一作用就是决定生成哪个版本的加减乘和数据转换的IL指令.
所以在checked操作符或语句中 调用方法,不会对该方法造成任何影响.
checked
{
Byte b = 100;
//简化 b = (Byte)(b + 200)
b += 200;
}
checked
{
// 假定SomeMethod试图把400加载到一个Byte中
SomeMethod(400);
// SomeMethod 可能会,也可能不会抛出OverflowException异常
// 如果SomeMethod使用checked指令编译,就可能会抛出异常.
// 但这和当前的checked语句无关.
}
应对无效输入的建议
尽量使用有
符号数值类型比如:Int32和Int64,而不是无符号数值类型UInt32和UInt64.- 这允许编译器检测更多的上溢/下溢的错误.
- 类库的多个部分,比如Array和String的Length属性 被硬编码为返回有符号的值.
- 减少强制类型转换,无符号数值类型不符合CLS.
写代码时,如果代码可能发生你想不到的溢出(可能是无效的输入,使用用户或客户机提供的数据), 就把这些代码放到
checked块中. 同时捕捉OverflowException异常.将允许发生溢出的代码显示放到
unchecked块中,比如在计算校验和时.对于没有使用
unchecked和checked的语句,都假定发生溢出时抛出异常.
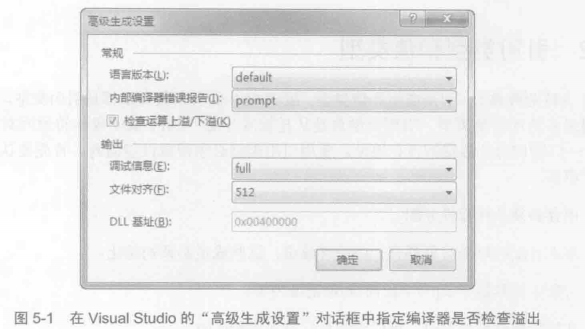
勾选 检查运算上溢/下溢 相当于打开了编译器的/checked+开关进行调试性生成.应用程序运行起来会慢一点.可以进行比较完整的溢出检查.
System.Decimal是非常特殊的类型
- C#和VB视为基元类型. 但是CLR不这样. CLR没有知道如何处理Decimal值的IL指令.
- Decimal类型自己定义一系列方法,包括Add,Subtract,Multiply,Divide. 还为
+-*/等提供了操作符重载方法. - 编译使用了Decimal值的代码时,编译器会生成代码来调用Decimal的成员方法,并通过这些成员方法来进行实际的运算. 这也意味着Decimal值的处理速度慢于CLR基元类型的值.
- 由于没有相应的IL指令来处理Decimal值, 所以checked和unchecked操作符,编译器开关都失去作用.
System.Numerics.BigInteger类型
- 类似的,BigInteger类型也在内部使用了
UInt32数组来表示任意大的整数,它的值没有上限和下限. - 因此对于BigInteger类型执行运算永远不会造成OverflowException异常
- 如果值太大,没有足够的内存来改变数组大小,BigInteger的运算可能会抛出
OutOfMemoryException异常.
